Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalization of Transliterated Words in Code-Mixed Data Using Seq2Seq Model & Levenshtein Distance
Paper and Code
May 22, 2018
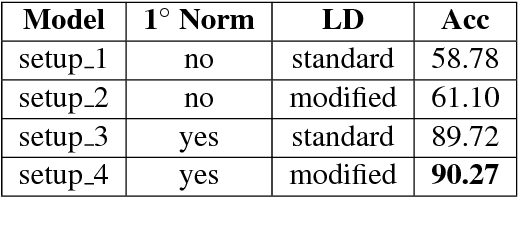
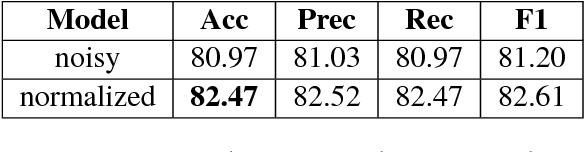
Building tools for code-mixed data is rapidly gaining popularity in the NLP research community as such data is exponentially rising on social media. Working with code-mixed data contains several challenges, especially due to grammatical inconsistencies and spelling variations in addition to all the previous known challenges for social media scenarios. In this article, we present a novel architecture focusing on normalizing phonetic typing variations, which is commonly seen in code-mixed data. One of the main features of our architecture is that in addition to normalizing, it can also be utilized for back-transliteration and word identification in some cases. Our model achieved an accuracy of 90.27% on the test data.
* 5 pages, 1 figure, 2 tables
View paper on