Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline normalizer calculation for softmax
Paper and Code
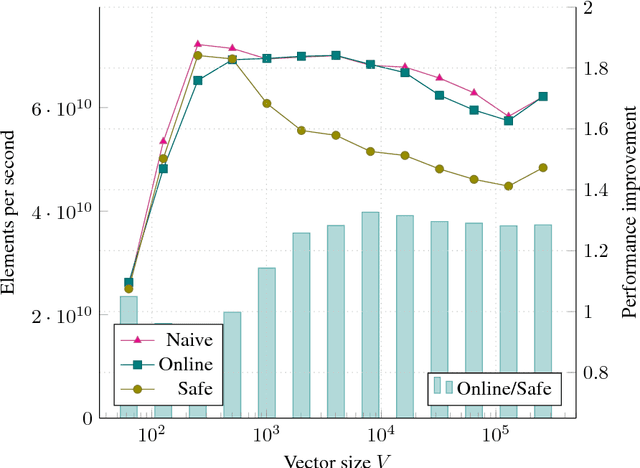
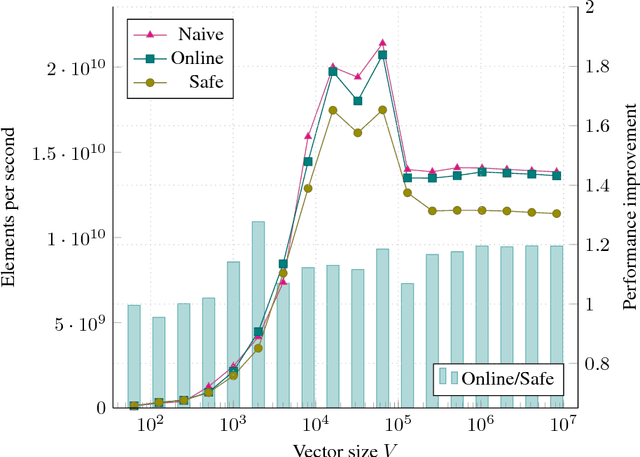
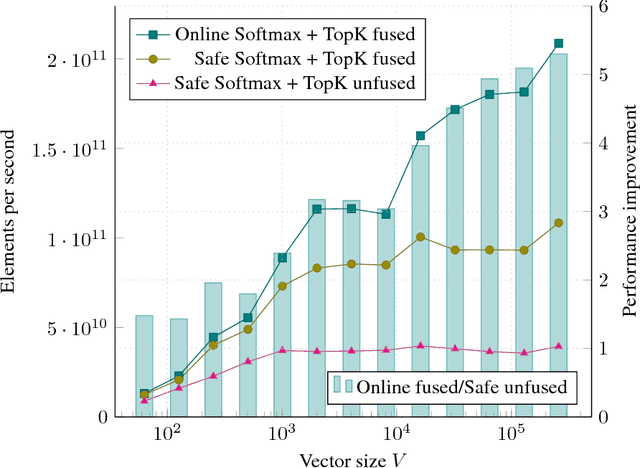
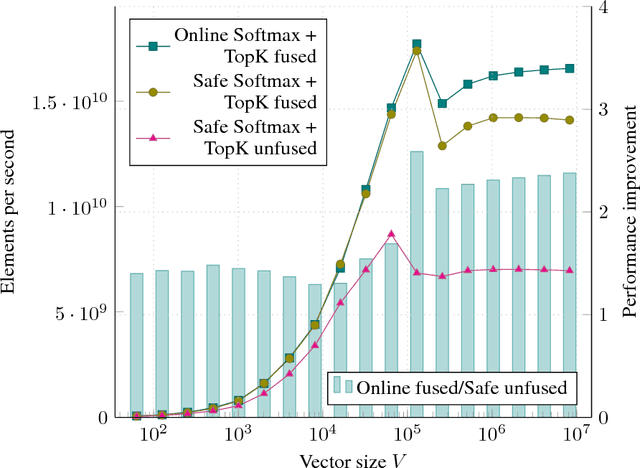
The Softmax function is ubiquitous in machine learning, multiple previous works suggested faster alternatives for it. In this paper we propose a way to compute classical Softmax with fewer memory accesses and hypothesize that this reduction in memory accesses should improve Softmax performance on actual hardware. The benchmarks confirm this hypothesis: Softmax accelerates by up to 1.3x and Softmax+TopK combined and fused by up to 5x.
* 1) Added link to the benchmark code, 2) Benchmarked Safe Softmax +
Top-K fused and attributed part of 5x explicitly to fusion in sections 5.2
and 6, 3) Stylistic changes, 4) Minor clarifications
View paper on