 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Alive Blurred Moments!
Paper and Code
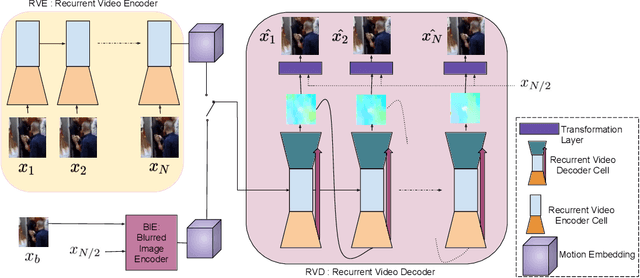
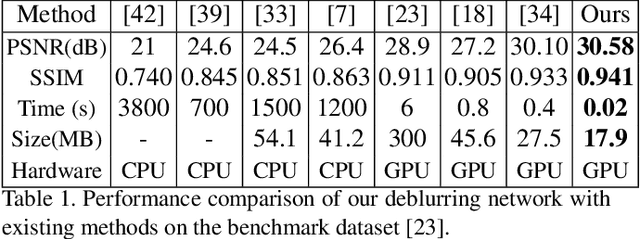
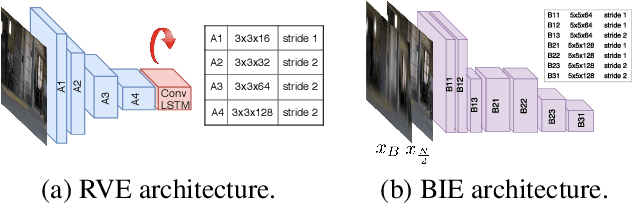
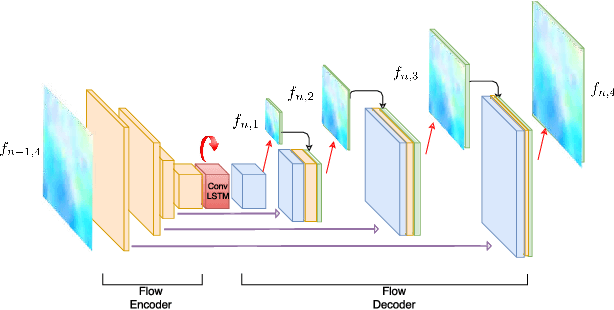
We present a solution for the novel goal of extracting a video from a single blurred image to sequentially reconstruct the views of a scene as beheld by the camera during the time of exposure. We approach this task by first learning a motion representation for videos in an unsupervised manner through training of a novel video autoencoder network that performs a surrogate task of video reconstruction. Instead of enforc- ing temporal constraints on features learned at the image level, we em- ploy a recurrent design with convolutional filters to directly learn tempo- rally correlated representations. Once trained, this network is employed for the guided training of a motion encoder for blurred images. This net- work extracts embedded motion information from a single blurred image so as to generate a sharp video in conjunction with the trained recur- rent video decoder. Experiments on real scenes and standard data-sets demonstrate our framework's ability to generate a plausible sequence of sharp frames.