 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Classification of Text Sentiment
Paper and Code
Apr 05, 2018
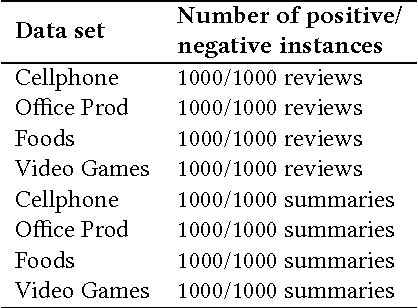


The ability to identify sentiment in text, referred to as sentiment analysis, is one which is natural to adult humans. This task is, however, not one which a computer can perform by default. Identifying sentiments in an automated, algorithmic manner will be a useful capability for business and research in their search to understand what consumers think about their products or services and to understand human sociology. Here we propose two new Genetic Algorithms (GAs) for the task of automated text sentiment analysis. The GAs learn whether words occurring in a text corpus are either sentiment or amplifier words, and their corresponding magnitude. Sentiment words, such as 'horrible', add linearly to the final sentiment. Amplifier words in contrast, which are typically adjectives/adverbs like 'very', multiply the sentiment of the following word. This increases, decreases or negates the sentiment of the following word. The sentiment of the full text is then the sum of these terms. This approach grows both a sentiment and amplifier dictionary which can be reused for other purposes and fed into other machine learning algorithms. We report the results of multiple experiments conducted on large Amazon data sets. The results reveal that our proposed approach was able to outperform several public and/or commercial sentiment analysis algorithms.