 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Regularized Losses for Weakly-supervised CNN Segmentation
Paper and Code
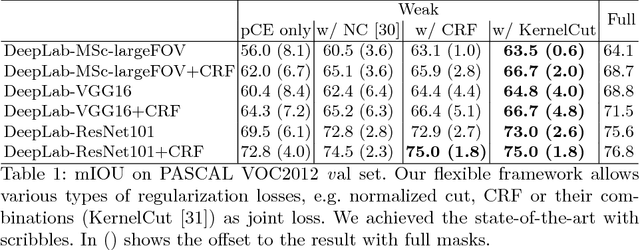
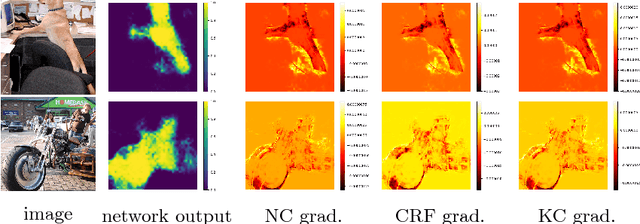
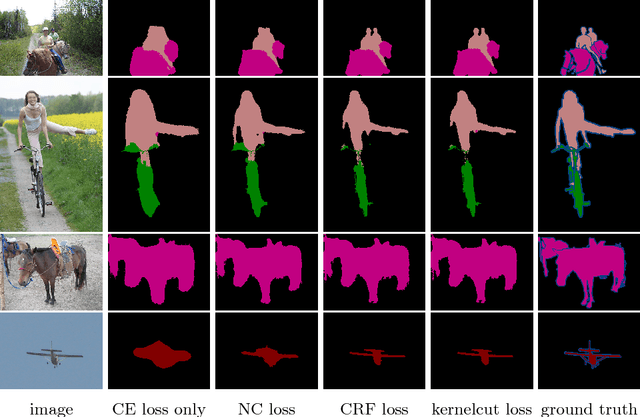
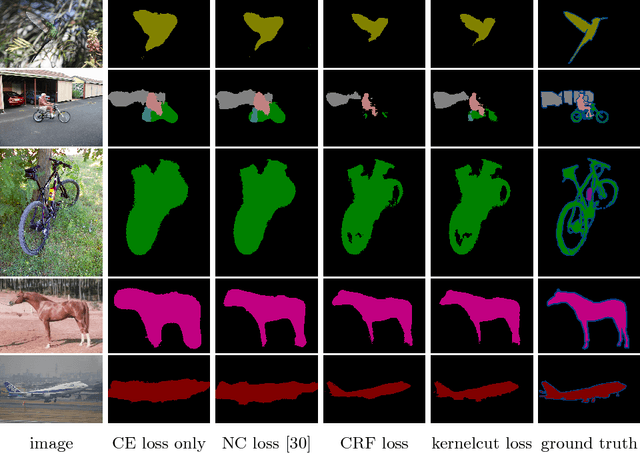
Minimization of regularized losses is a principled approach to weak supervision well-established in deep learning, in general. However, it is largely overlooked in semantic segmentation currently dominated by methods mimicking full supervision via "fake" fully-labeled training masks (proposals) generated from available partial input. To obtain such full masks the typical methods explicitly use standard regularization techniques for "shallow" segmentation, e.g. graph cuts or dense CRFs. In contrast, we integrate such standard regularizers directly into the loss functions over partial input. This approach simplifies weakly-supervised training by avoiding extra MRF/CRF inference steps or layers explicitly generating full masks, while improving both the quality and efficiency of training. This paper proposes and experimentally compares different losses integrating MRF/CRF regularization terms. We juxtapose our regularized losses with earlier proposal-generation methods using explicit regularization steps or layers. Our approach achieves state-of-the-art accuracy in semantic segmentation with near full-supervision quality.