 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Discriminating Profanity from Hate Speech
Paper and Code
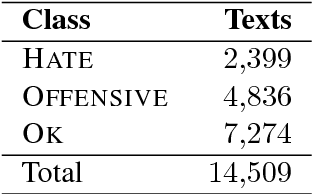

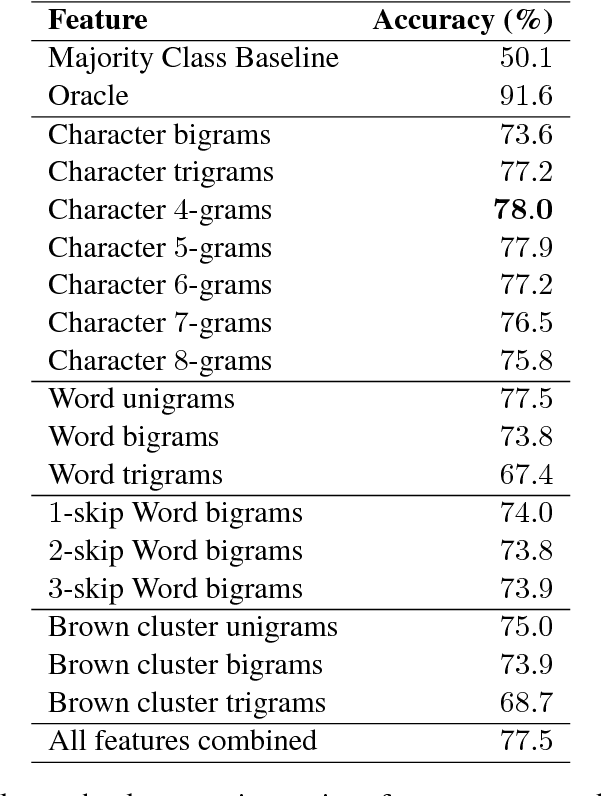
In this study we approach the problem of distinguishing general profanity from hate speech in social media, something which has not been widely considered. Using a new dataset annotated specifically for this task, we employ supervised classification along with a set of features that includes n-grams, skip-grams and clustering-based word representations. We apply approaches based on single classifiers as well as more advanced ensemble classifiers and stacked generalization, achieving the best result of 80% accuracy for this 3-class classification task. Analysis of the results reveals that discriminating hate speech and profanity is not a simple task, which may require features that capture a deeper understanding of the text not always possible with surface n-grams. The variability of gold labels in the annotated data, due to differences in the subjective adjudications of the annotators, is also an issue. Other directions for future work are discussed.