 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTicTac: Accelerating Distributed Deep Learning with Communication Scheduling
Paper and Code
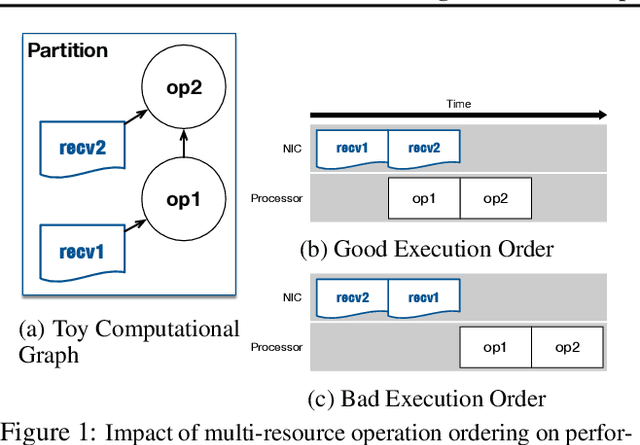
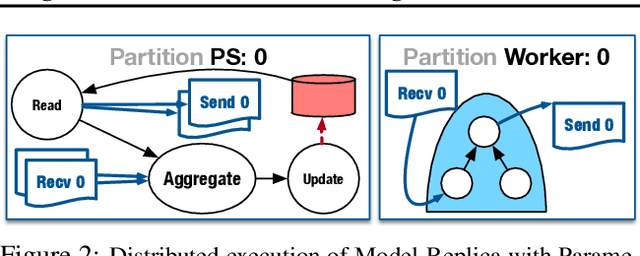
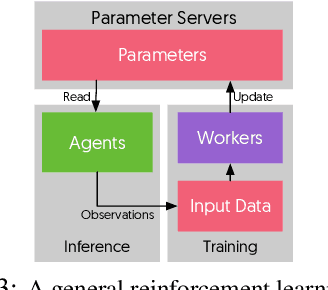
State-of-the-art deep learning systems rely on iterative distributed training to tackle the increasing complexity of models and input data. The iteration time in these communication-heavy systems depends on the computation time, communication time and the extent of overlap of computation and communication. In this work, we identify a shortcoming in systems with graph representation for computation, such as TensorFlow and PyTorch, that result in high variance in iteration time --- random order of received parameters across workers. We develop a system, TicTac, to improve the iteration time by fixing this issue in distributed deep learning with Parameter Servers while guaranteeing near-optimal overlap of communication and computation. TicTac identifies and enforces an order of network transfers which improves the iteration time using prioritization. Our system is implemented over TensorFlow and requires no changes to the model or developer inputs. TicTac improves the throughput by up to $37.7\%$ in inference and $19.2\%$ in training, while also reducing straggler effect by up to $2.3\times$. Our code is publicly available.