 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Word-Character Approach to Abstractive Summarization
Paper and Code
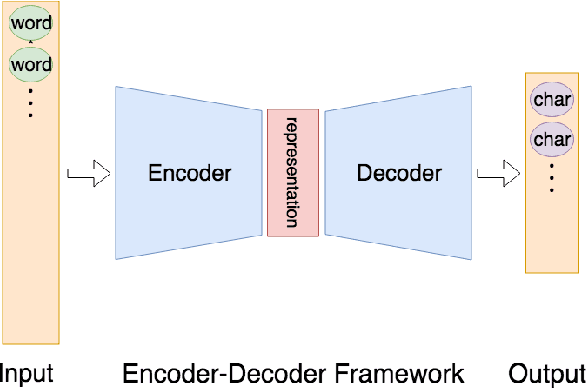
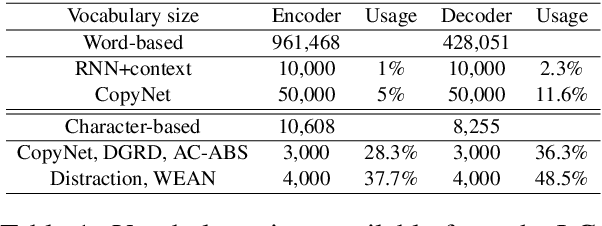
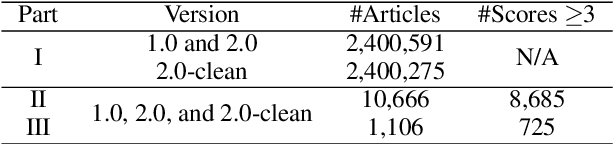
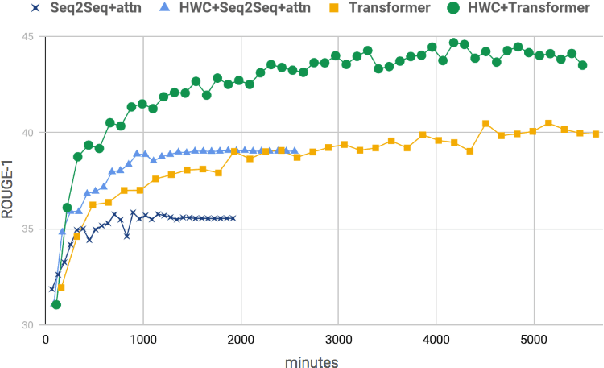
Automatic abstractive text summarization is an important and challenging research topic of natural language processing. Among many widely used languages, the Chinese language has a special property that a Chinese character contains rich information comparable to a word. Existing Chinese text summarization methods, either adopt totally character-based or word-based representations, fail to fully exploit the information carried by both representations. To accurately capture the essence of articles, we propose a hybrid word-character approach (HWC) which preserves the advantages of both word-based and character-based representations. We evaluate the advantage of the proposed HWC approach by applying it to two existing methods, and discover that it generates state-of-the-art performance with a margin of 24 ROUGE points on a widely used dataset LCSTS. In addition, we find an issue contained in the LCSTS dataset and offer a script to remove overlapping pairs (a summary and a short text) to create a clean dataset for the community. The proposed HWC approach also generates the best performance on the new, clean LCSTS dataset.