 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable kernel-based variable selection with sparsistency
Paper and Code
Feb 27, 2018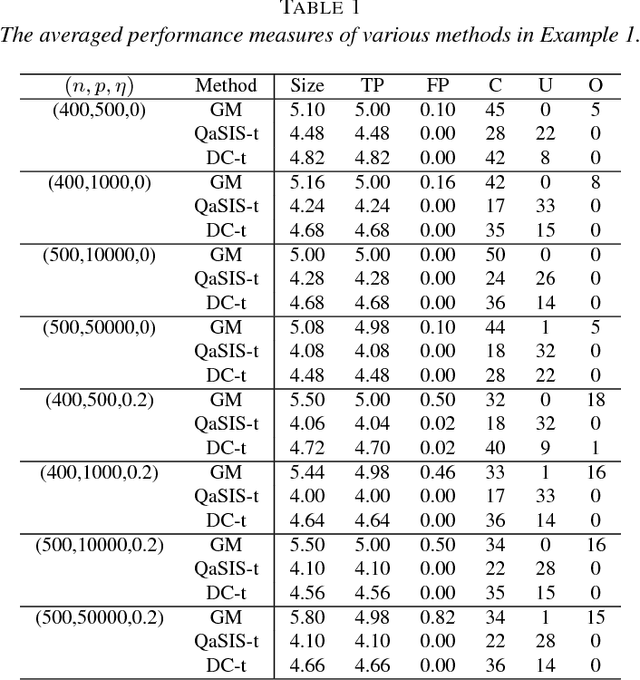
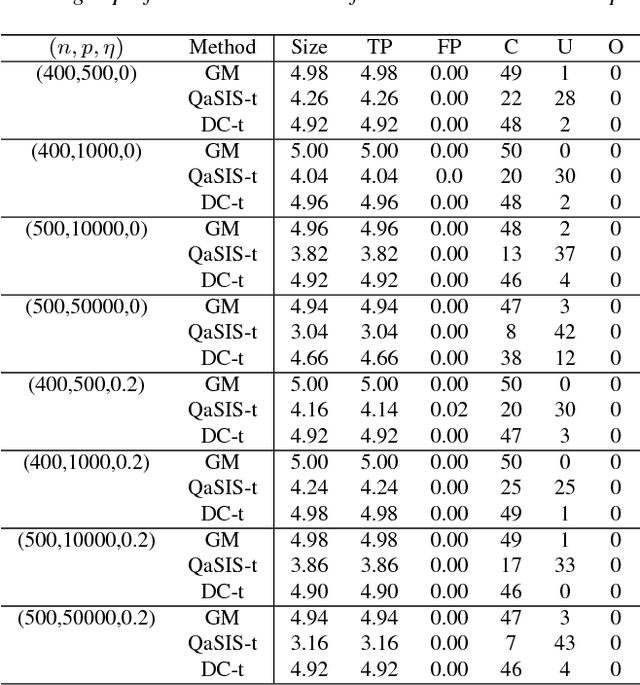
Variable selection is central to high-dimensional data analysis, and various algorithms have been developed. Ideally, a variable selection algorithm shall be flexible, scalable, and with theoretical guarantee, yet most existing algorithms cannot attain these properties at the same time. In this article, a three-step variable selection algorithm is developed, involving kernel-based estimation of the regression function and its gradient functions as well as a hard thresholding. Its key advantage is that it assumes no explicit model assumption, admits general predictor effects, allows for scalable computation, and attains desirable asymptotic sparsistency. The proposed algorithm can be adapted to any reproducing kernel Hilbert space (RKHS) with different kernel functions, and can be extended to interaction selection with slight modification. Its computational cost is only linear in the data dimension, and can be further improved through parallel computing. The sparsistency of the proposed algorithm is established for general RKHS under mild conditions, including linear and Gaussian kernels as special cases. Its effectiveness is also supported by a variety of simulated and real examples.