 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Reinforcement Learning in Asynchronous Environments
Paper and Code
Feb 16, 2018
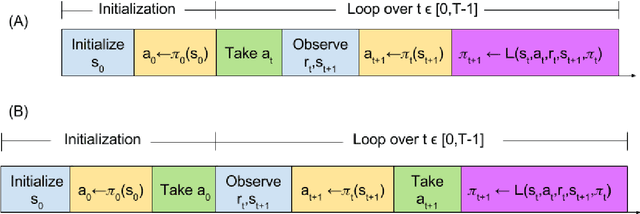

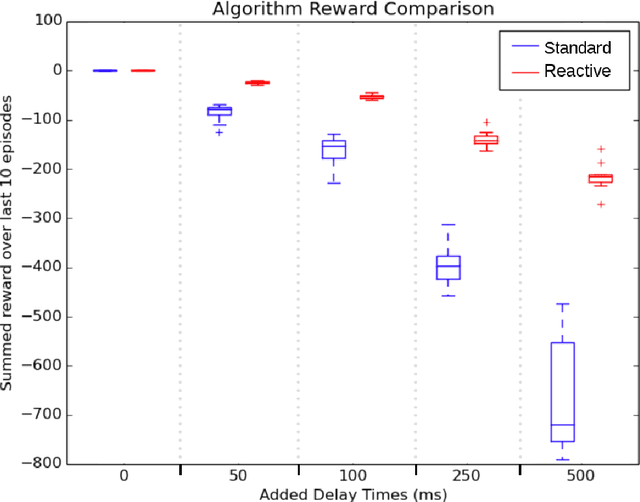
The relationship between a reinforcement learning (RL) agent and an asynchronous environment is often ignored. Frequently used models of the interaction between an agent and its environment, such as Markov Decision Processes (MDP) or Semi-Markov Decision Processes (SMDP), do not capture the fact that, in an asynchronous environment, the state of the environment may change during computation performed by the agent. In an asynchronous environment, minimizing reaction time---the time it takes for an agent to react to an observation---also minimizes the time in which the state of the environment may change following observation. In many environments, the reaction time of an agent directly impacts task performance by permitting the environment to transition into either an undesirable terminal state or a state where performing the chosen action is inappropriate. We propose a class of reactive reinforcement learning algorithms that address this problem of asynchronous environments by immediately acting after observing new state information. We compare a reactive SARSA learning algorithm with the conventional SARSA learning algorithm on two asynchronous robotic tasks (emergency stopping and impact prevention), and show that the reactive RL algorithm reduces the reaction time of the agent by approximately the duration of the algorithm's learning update. This new class of reactive algorithms may facilitate safer control and faster decision making without any change to standard learning guarantees.