 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Past Mistakes: Improving Automatic Speech Recognition Output via Noisy-Clean Phrase Context Modeling
Paper and Code
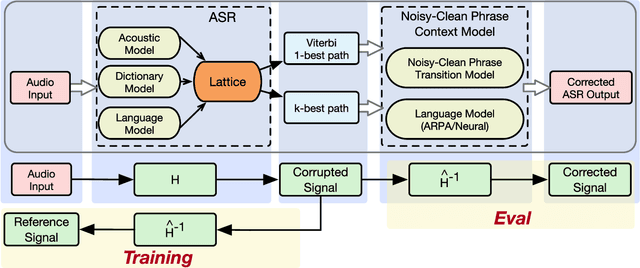

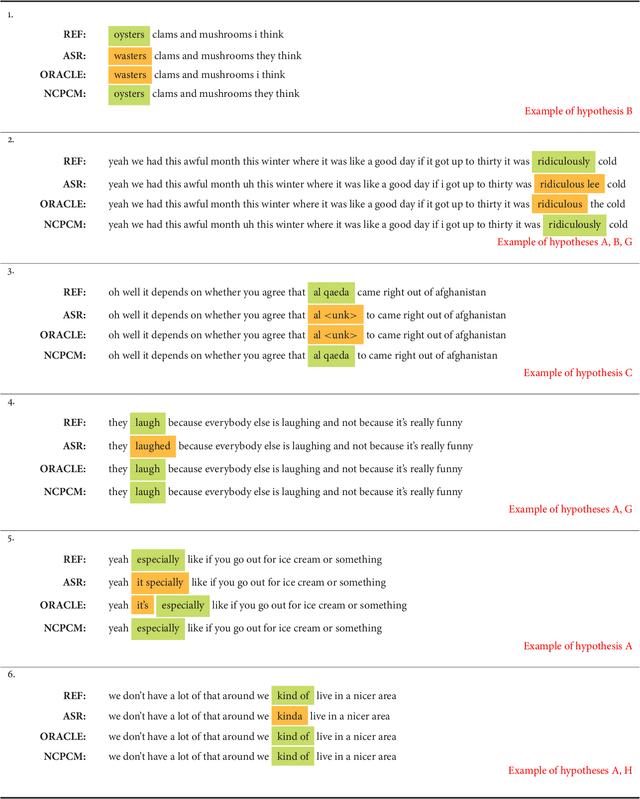
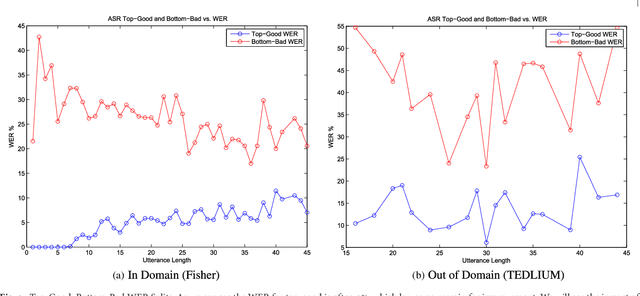
Automatic speech recognition (ASR) systems lack joint optimization during decoding over the acoustic, lexical and language models; for instance the ASR will often prune words due to acoustics using short-term context, prior to rescoring with long-term context. In this work we model the automated speech transcription process as a noisy transformation channel and propose an error correction system that can learn from the aggregate errors of all the independent modules constituting the ASR. The proposed system can exploit long-term context using a neural network language model and can better choose between existing ASR output possibilities as well as re-introduce previously pruned and unseen (out-of-vocabulary) phrases. The system provides significant corrections under poorly performing ASR conditions without degrading any accurate transcriptions. The proposed system can thus be independently optimized and post-process the output of even a highly optimized ASR. We show that the system consistently provides improvements over the baseline ASR. We also show that it performs better when used on out-of-domain and mismatched test data and under high-error ASR conditions. Finally, an extensive analysis of the type of errors corrected by our system is presented.