 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Deep Actor-Critic Reinforcement Learning Algorithms With Expert Demonstrations
Paper and Code
Feb 09, 2018
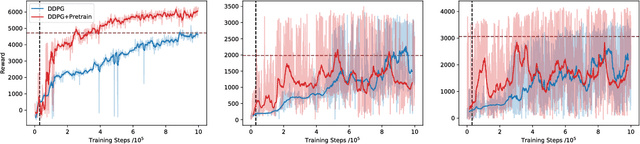
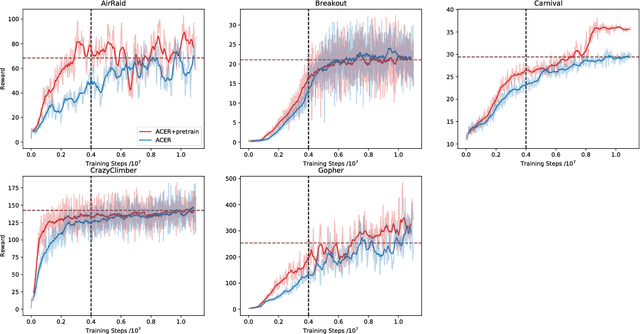
Pretraining with expert demonstrations have been found useful in speeding up the training process of deep reinforcement learning algorithms since less online simulation data is required. Some people use supervised learning to speed up the process of feature learning, others pretrain the policies by imitating expert demonstrations. However, these methods are unstable and not suitable for actor-critic reinforcement learning algorithms. Also, some existing methods rely on the global optimum assumption, which is not true in most scenarios. In this paper, we employ expert demonstrations in a actor-critic reinforcement learning framework, and meanwhile ensure that the performance is not affected by the fact that expert demonstrations are not global optimal. We theoretically derive a method for computing policy gradients and value estimators with only expert demonstrations. Our method is theoretically plausible for actor-critic reinforcement learning algorithms that pretrains both policy and value functions. We apply our method to two of the typical actor-critic reinforcement learning algorithms, DDPG and ACER, and demonstrate with experiments that our method not only outperforms the RL algorithms without pretraining process, but also is more simulation efficient.