Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient descent revisited via an adaptive online learning rate
Paper and Code
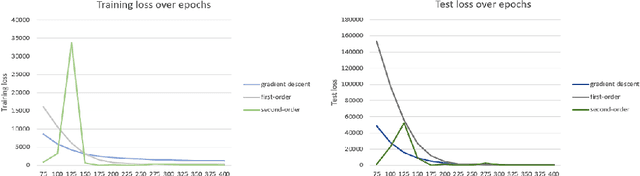
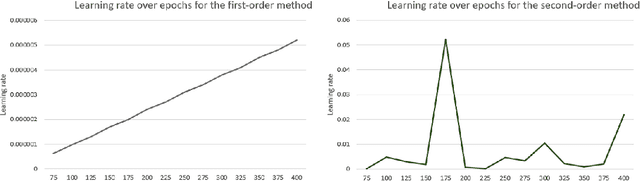
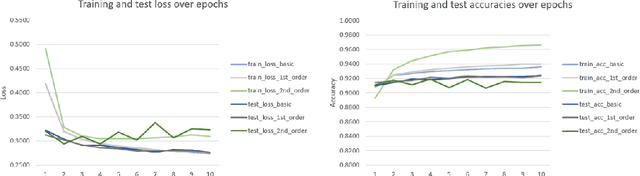
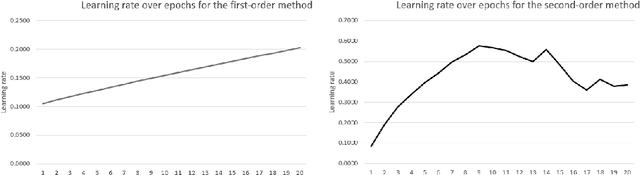
Any gradient descent optimization requires to choose a learning rate. With deeper and deeper models, tuning that learning rate can easily become tedious and does not necessarily lead to an ideal convergence. We propose a variation of the gradient descent algorithm in the which the learning rate is not fixed. Instead, we learn the learning rate itself, either by another gradient descent (first-order method), or by Newton's method (second-order). This way, gradient descent for any machine learning algorithm can be optimized.
View paper on