 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Kronecker Component Analysis
Paper and Code
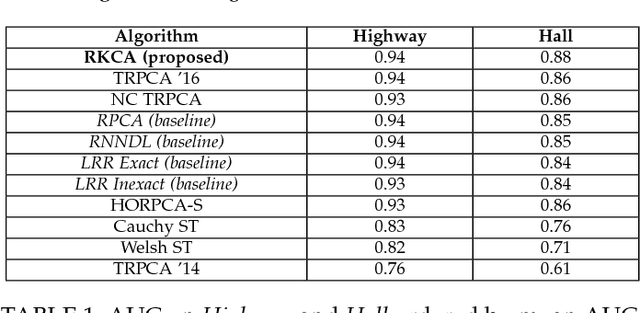
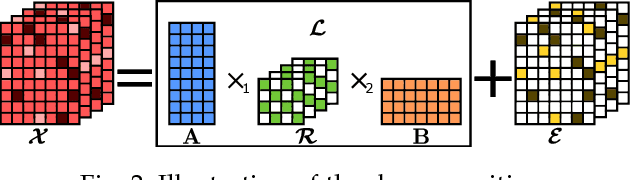
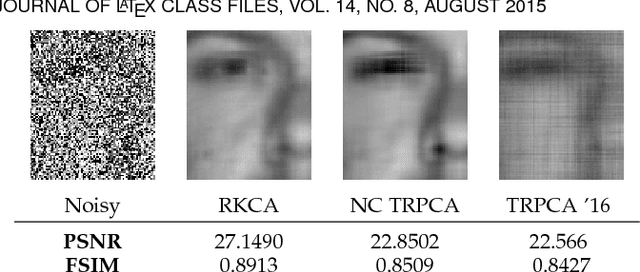
Dictionary learning and component analysis models are fundamental in learning compact representations that are relevant to a given task (feature extraction, dimensionality reduction, denoising, etc.). The model complexity is encoded by means of specific structure, such as sparsity, low-rankness, or nonnegativity. Unfortunately, approaches like K-SVD - that learn dictionaries for sparse coding via Singular Value Decomposition (SVD) - are hard to scale to high-volume and high-dimensional visual data, and fragile in the presence of outliers. Conversely, robust component analysis methods such as the Robust Principle Component Analysis (RPCA) are able to recover low-complexity (e.g., low-rank) representations from data corrupted with noise of unknown magnitude and support, but do not provide a dictionary that respects the structure of the data (e.g., images), and also involve expensive computations. In this paper, we propose a novel Kronecker-decomposable component analysis model, coined as Robust Kronecker Component Analysis (RKCA), that combines ideas from sparse dictionary learning and robust component analysis. RKCA has several appealing properties, including robustness to gross corruption; it can be used for low-rank modeling, and leverages separability to solve significantly smaller problems. We design an efficient learning algorithm by drawing links with a restricted form of tensor factorization, and analyze its optimality and low-rankness properties. The effectiveness of the proposed approach is demonstrated on real-world applications, namely background subtraction and image denoising and completion, by performing a thorough comparison with the current state of the art.