 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Culling the Training Set to Improve Robustness of Deep Neural Networks
Paper and Code
Jan 09, 2018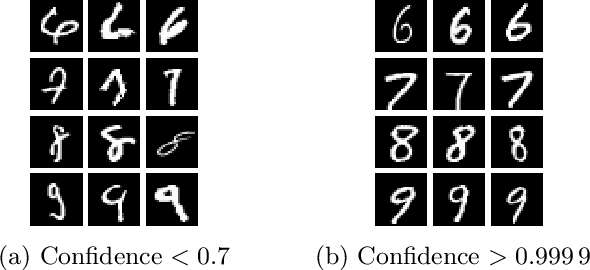

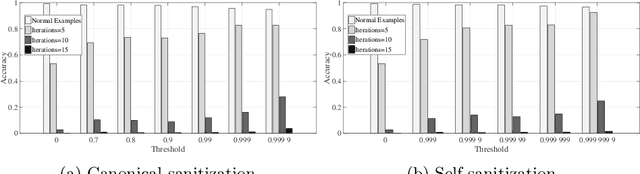
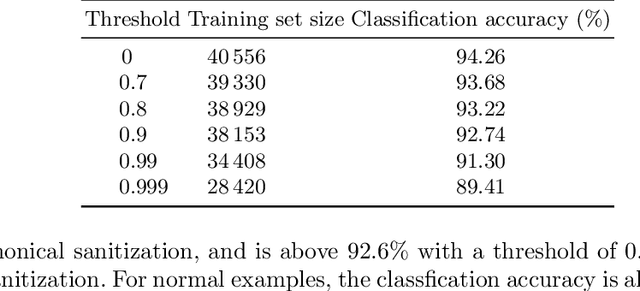
Deep neural networks are vulnerable to adversarial examples. Prior defenses attempted to make deep networks more robust by either improving the network architecture or adding adversarial examples into the training set, with their respective limitations. We propose a new direction. Motivated by recent research that shows that outliers in the training set have a high negative influence on the trained model, our approach makes the model more robust by detecting and removing outliers in the training set without modifying the network architecture or requiring adversarial examples. We propose two methods for detecting outliers based on canonical examples and on training errors, respectively. After removing the outliers, we train the classifier with the remaining examples to obtain a sanitized model. Our evaluation shows that the sanitized model improves classification accuracy and forces the attacks to generate adversarial examples with higher distortions. Moreover, the Kullback-Leibler divergence from the output of the original model to that of the sanitized model allows us to distinguish between normal and adversarial examples reliably.