 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Architectures, Data and Units For Streaming End-to-End Speech Recognition with RNN-Transducer
Paper and Code
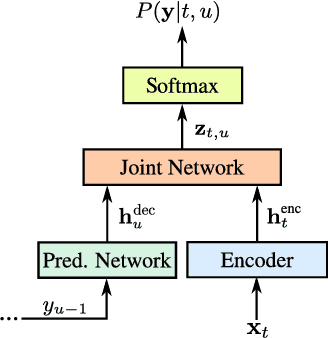
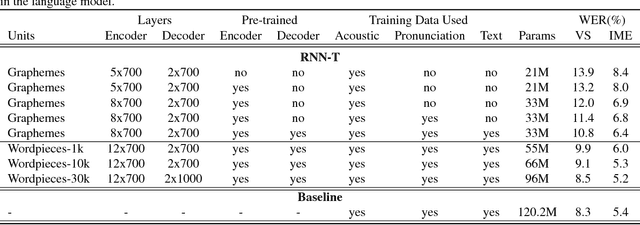
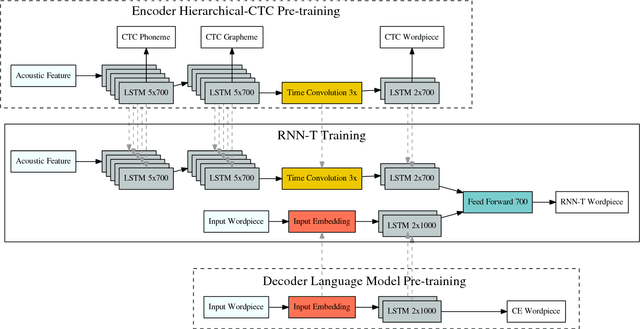
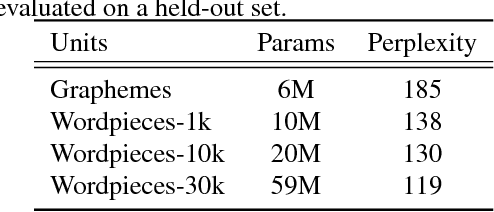
We investigate training end-to-end speech recognition models with the recurrent neural network transducer (RNN-T): a streaming, all-neural, sequence-to-sequence architecture which jointly learns acoustic and language model components from transcribed acoustic data. We explore various model architectures and demonstrate how the model can be improved further if additional text or pronunciation data are available. The model consists of an `encoder', which is initialized from a connectionist temporal classification-based (CTC) acoustic model, and a `decoder' which is partially initialized from a recurrent neural network language model trained on text data alone. The entire neural network is trained with the RNN-T loss and directly outputs the recognized transcript as a sequence of graphemes, thus performing end-to-end speech recognition. We find that performance can be improved further through the use of sub-word units (`wordpieces') which capture longer context and significantly reduce substitution errors. The best RNN-T system, a twelve-layer LSTM encoder with a two-layer LSTM decoder trained with 30,000 wordpieces as output targets achieves a word error rate of 8.5\% on voice-search and 5.2\% on voice-dictation tasks and is comparable to a state-of-the-art baseline at 8.3\% on voice-search and 5.4\% voice-dictation.