Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversary Detection in Neural Networks via Persistent Homology
Paper and Code
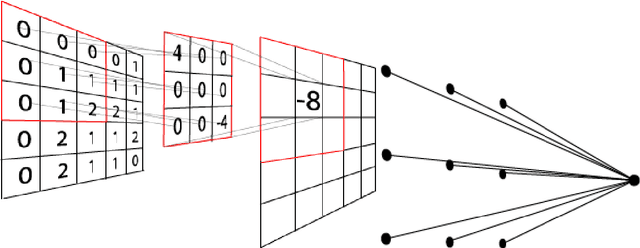



We outline a detection method for adversarial inputs to deep neural networks. By viewing neural network computations as graphs upon which information flows from input space to out- put distribution, we compare the differences in graphs induced by different inputs. Specifically, by applying persistent homology to these induced graphs, we observe that the structure of the most persistent subgraphs which generate the first homology group differ between adversarial and unperturbed inputs. Based on this observation, we build a detection algorithm that depends only on the topological information extracted during training. We test our algorithm on MNIST and achieve 98% detection adversary accuracy with F1-score 0.98.
* 16 pages
View paper on