 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Accuracy of Pre-trained Word Embeddings for Sentiment Analysis
Paper and Code
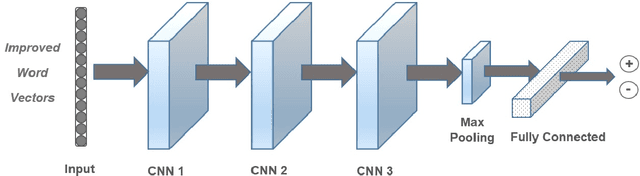
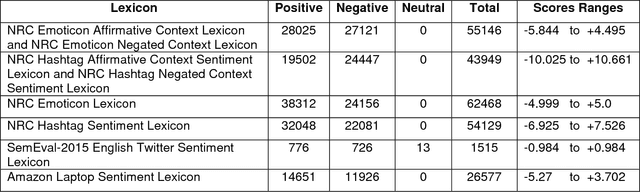
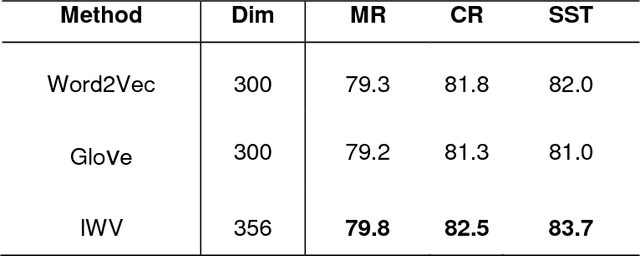
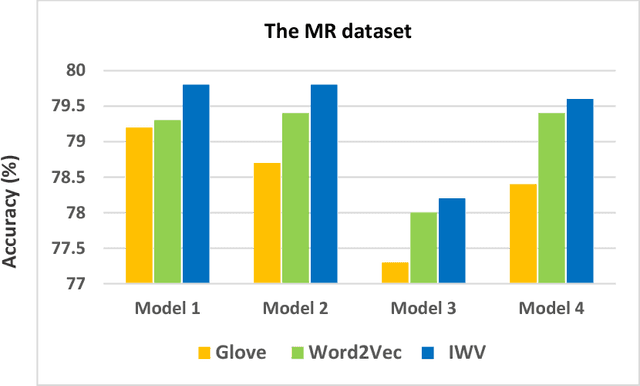
Sentiment analysis is one of the well-known tasks and fast growing research areas in natural language processing (NLP) and text classifications. This technique has become an essential part of a wide range of applications including politics, business, advertising and marketing. There are various techniques for sentiment analysis, but recently word embeddings methods have been widely used in sentiment classification tasks. Word2Vec and GloVe are currently among the most accurate and usable word embedding methods which can convert words into meaningful vectors. However, these methods ignore sentiment information of texts and need a huge corpus of texts for training and generating exact vectors which are used as inputs of deep learning models. As a result, because of the small size of some corpuses, researcher often have to use pre-trained word embeddings which were trained on other large text corpus such as Google News with about 100 billion words. The increasing accuracy of pre-trained word embeddings has a great impact on sentiment analysis research. In this paper we propose a novel method, Improved Word Vectors (IWV), which increases the accuracy of pre-trained word embeddings in sentiment analysis. Our method is based on Part-of-Speech (POS) tagging techniques, lexicon-based approaches and Word2Vec/GloVe methods. We tested the accuracy of our method via different deep learning models and sentiment datasets. Our experiment results show that Improved Word Vectors (IWV) are very effective for sentiment analysis.