 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Phenomenon in the Eyes of Bayesian Deep Learning
Paper and Code
Nov 22, 2017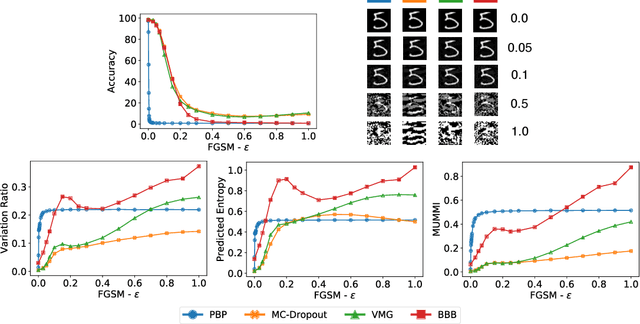
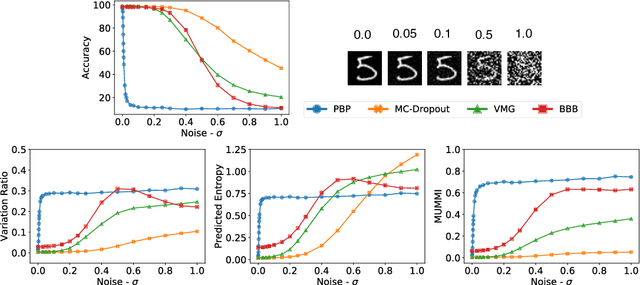
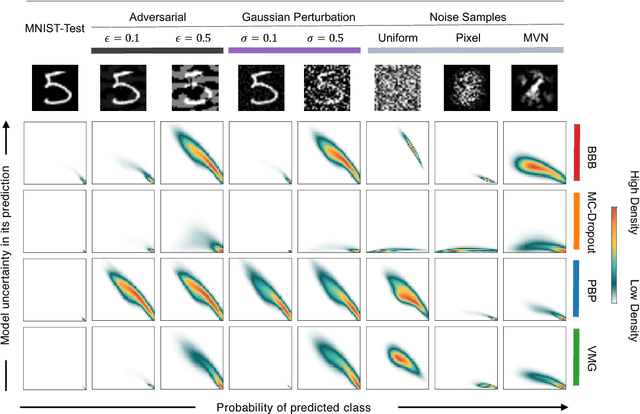
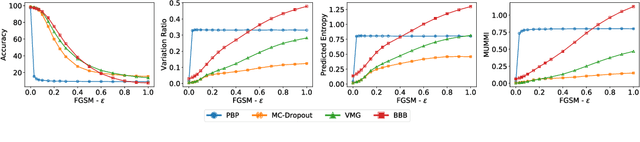
Deep Learning models are vulnerable to adversarial examples, i.e.\ images obtained via deliberate imperceptible perturbations, such that the model misclassifies them with high confidence. However, class confidence by itself is an incomplete picture of uncertainty. We therefore use principled Bayesian methods to capture model uncertainty in prediction for observing adversarial misclassification. We provide an extensive study with different Bayesian neural networks attacked in both white-box and black-box setups. The behaviour of the networks for noise, attacks and clean test data is compared. We observe that Bayesian neural networks are uncertain in their predictions for adversarial perturbations, a behaviour similar to the one observed for random Gaussian perturbations. Thus, we conclude that Bayesian neural networks can be considered for detecting adversarial examples.