Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Morphological Expansion of Small Datasets for Improving Word Embeddings
Paper and Code
Nov 15, 2017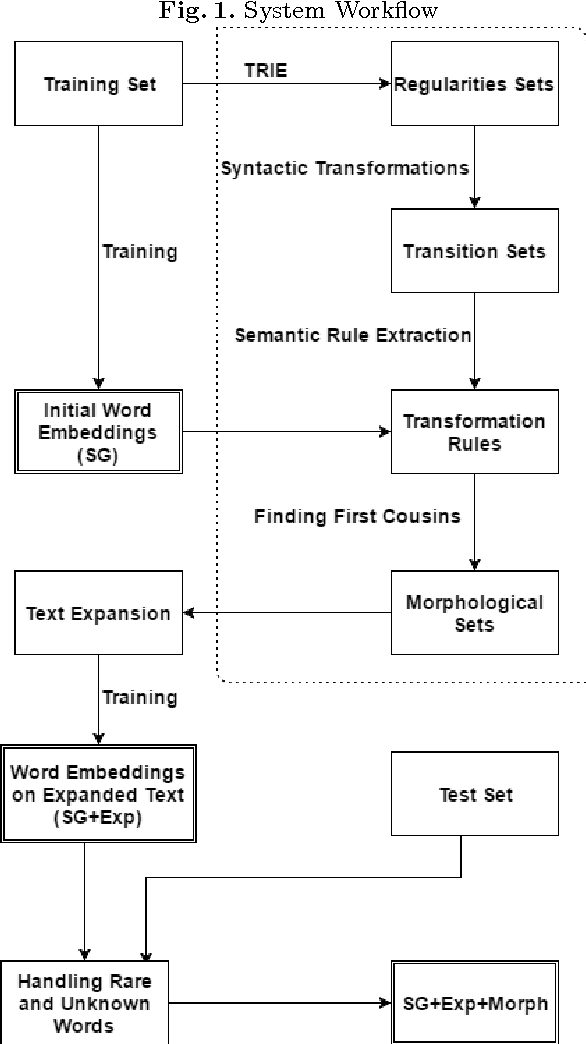


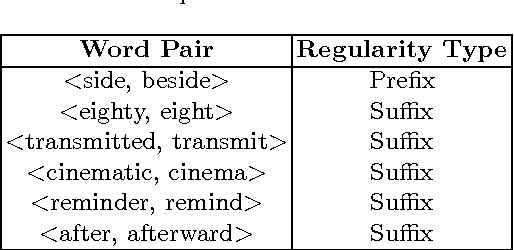
We present a language independent, unsupervised method for building word embeddings using morphological expansion of text. Our model handles the problem of data sparsity and yields improved word embeddings by relying on training word embeddings on artificially generated sentences. We evaluate our method using small sized training sets on eleven test sets for the word similarity task across seven languages. Further, for English, we evaluated the impacts of our approach using a large training set on three standard test sets. Our method improved results across all languages.
* CICLing 2017
View paper on