 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon Representation Learning Using Step-based Correlation Multi-Modal CNN
Paper and Code
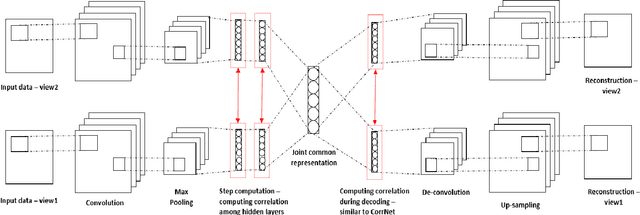
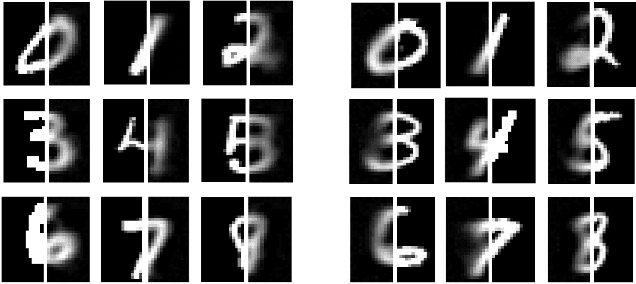
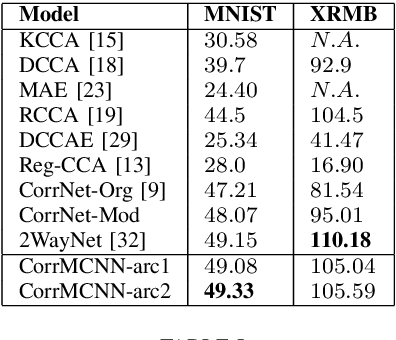
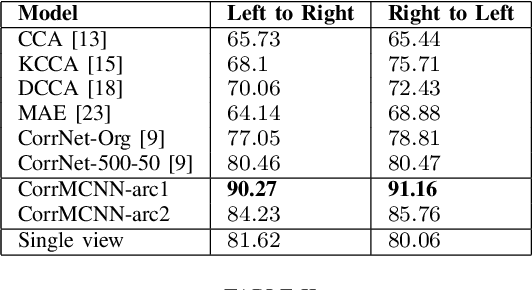
Deep learning techniques have been successfully used in learning a common representation for multi-view data, wherein the different modalities are projected onto a common subspace. In a broader perspective, the techniques used to investigate common representation learning falls under the categories of canonical correlation-based approaches and autoencoder based approaches. In this paper, we investigate the performance of deep autoencoder based methods on multi-view data. We propose a novel step-based correlation multi-modal CNN (CorrMCNN) which reconstructs one view of the data given the other while increasing the interaction between the representations at each hidden layer or every intermediate step. Finally, we evaluate the performance of the proposed model on two benchmark datasets - MNIST and XRMB. Through extensive experiments, we find that the proposed model achieves better performance than the current state-of-the-art techniques on joint common representation learning and transfer learning tasks.