 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Recognition Challenge in the Wild: Arabic MGB-3
Paper and Code
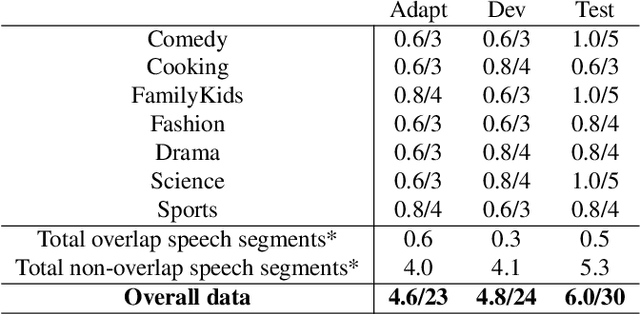
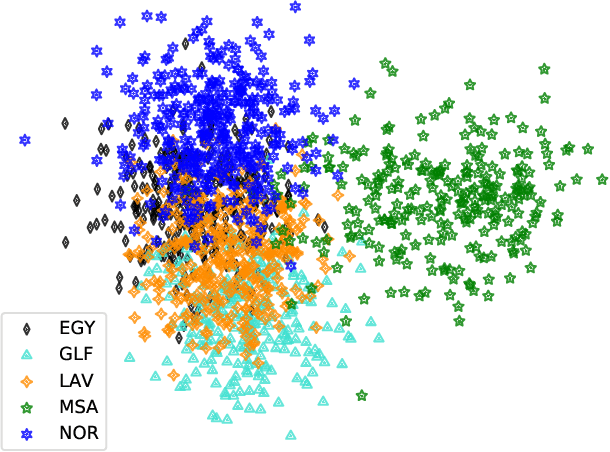

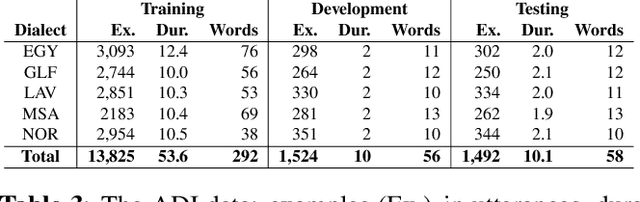
This paper describes the Arabic MGB-3 Challenge - Arabic Speech Recognition in the Wild. Unlike last year's Arabic MGB-2 Challenge, for which the recognition task was based on more than 1,200 hours broadcast TV news recordings from Aljazeera Arabic TV programs, MGB-3 emphasises dialectal Arabic using a multi-genre collection of Egyptian YouTube videos. Seven genres were used for the data collection: comedy, cooking, family/kids, fashion, drama, sports, and science (TEDx). A total of 16 hours of videos, split evenly across the different genres, were divided into adaptation, development and evaluation data sets. The Arabic MGB-Challenge comprised two tasks: A) Speech transcription, evaluated on the MGB-3 test set, along with the 10 hour MGB-2 test set to report progress on the MGB-2 evaluation; B) Arabic dialect identification, introduced this year in order to distinguish between four major Arabic dialects - Egyptian, Levantine, North African, Gulf, as well as Modern Standard Arabic. Two hours of audio per dialect were released for development and a further two hours were used for evaluation. For dialect identification, both lexical features and i-vector bottleneck features were shared with participants in addition to the raw audio recordings. Overall, thirteen teams submitted ten systems to the challenge. We outline the approaches adopted in each system, and summarise the evaluation results.