 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear Optimal Sketching of Low-Rank Tensor Regression
Paper and Code
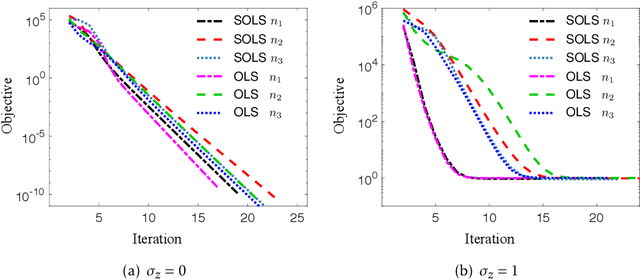
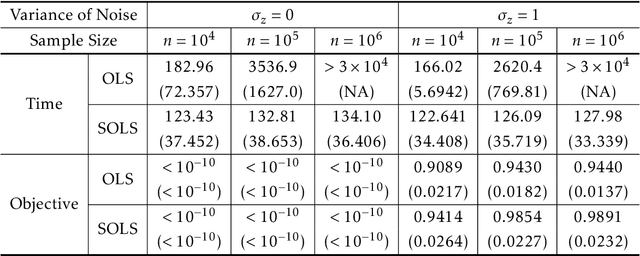
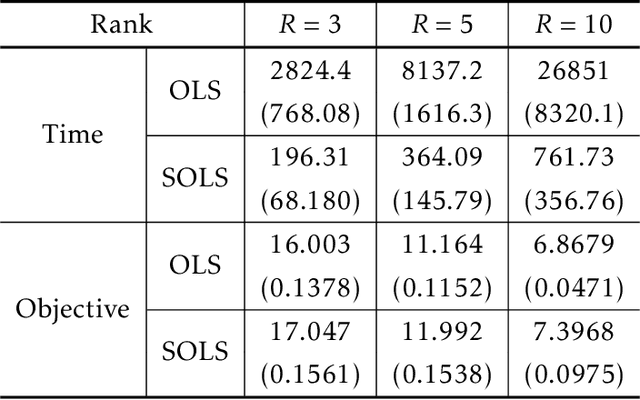
We study the least squares regression problem \begin{align*} \min_{\Theta \in \mathcal{S}_{\odot D,R}} \|A\Theta-b\|_2, \end{align*} where $\mathcal{S}_{\odot D,R}$ is the set of $\Theta$ for which $\Theta = \sum_{r=1}^{R} \theta_1^{(r)} \circ \cdots \circ \theta_D^{(r)}$ for vectors $\theta_d^{(r)} \in \mathbb{R}^{p_d}$ for all $r \in [R]$ and $d \in [D]$, and $\circ$ denotes the outer product of vectors. That is, $\Theta$ is a low-dimensional, low-rank tensor. This is motivated by the fact that the number of parameters in $\Theta$ is only $R \cdot \sum_{d=1}^D p_d$, which is significantly smaller than the $\prod_{d=1}^{D} p_d$ number of parameters in ordinary least squares regression. We consider the above CP decomposition model of tensors $\Theta$, as well as the Tucker decomposition. For both models we show how to apply data dimensionality reduction techniques based on {\it sparse} random projections $\Phi \in \mathbb{R}^{m \times n}$, with $m \ll n$, to reduce the problem to a much smaller problem $\min_{\Theta} \|\Phi A \Theta - \Phi b\|_2$, for which if $\Theta'$ is a near-optimum to the smaller problem, then it is also a near optimum to the original problem. We obtain significantly smaller dimension and sparsity in $\Phi$ than is possible for ordinary least squares regression, and we also provide a number of numerical simulations supporting our theory.