 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Training Large-Scale Deep Architectures
Paper and Code
Aug 10, 2017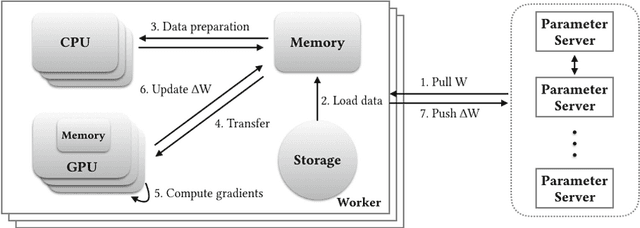
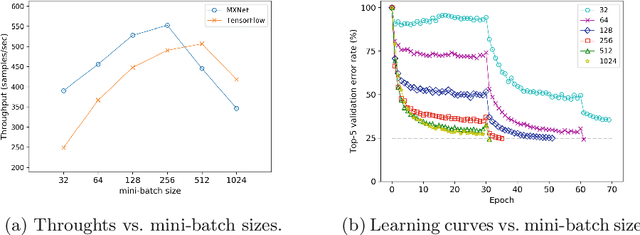
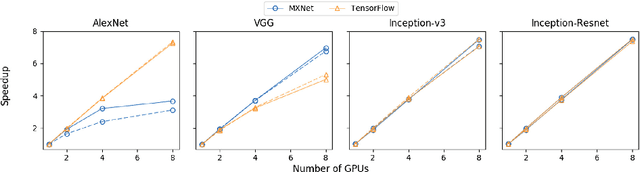
Scale of data and scale of computation infrastructures together enable the current deep learning renaissance. However, training large-scale deep architectures demands both algorithmic improvement and careful system configuration. In this paper, we focus on employing the system approach to speed up large-scale training. Via lessons learned from our routine benchmarking effort, we first identify bottlenecks and overheads that hinter data parallelism. We then devise guidelines that help practitioners to configure an effective system and fine-tune parameters to achieve desired speedup. Specifically, we develop a procedure for setting minibatch size and choosing computation algorithms. We also derive lemmas for determining the quantity of key components such as the number of GPUs and parameter servers. Experiments and examples show that these guidelines help effectively speed up large-scale deep learning training.