Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating SGD for Distributed Deep-Learning Using Approximated Hessian Matrix
Paper and Code
Sep 15, 2017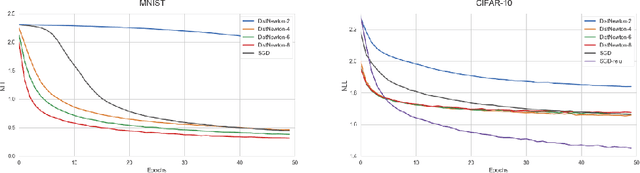
We introduce a novel method to compute a rank $m$ approximation of the inverse of the Hessian matrix in the distributed regime. By leveraging the differences in gradients and parameters of multiple Workers, we are able to efficiently implement a distributed approximation of the Newton-Raphson method. We also present preliminary results which underline advantages and challenges of second-order methods for large stochastic optimization problems. In particular, our work suggests that novel strategies for combining gradients provide further information on the loss surface.
* ICLR17 Workshop Track
View paper on