 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting Reliable Annotations for Sarcasm in Online Dialogues
Paper and Code
Sep 04, 2017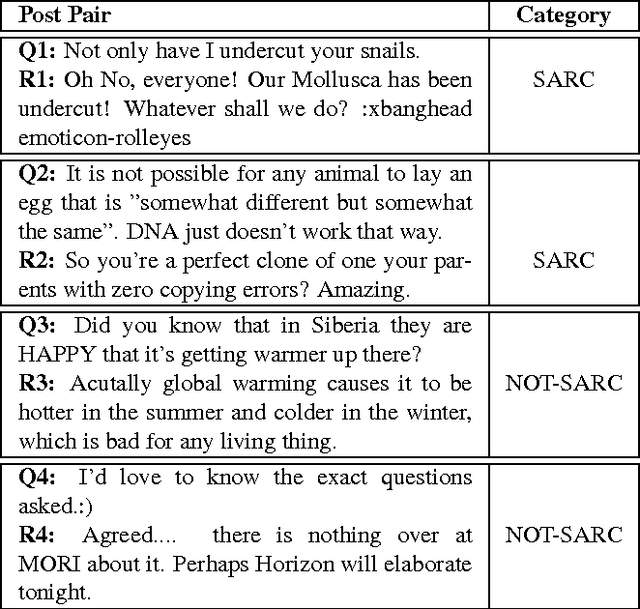
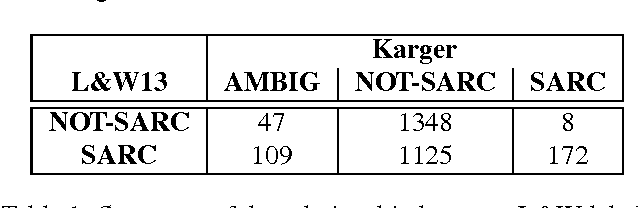
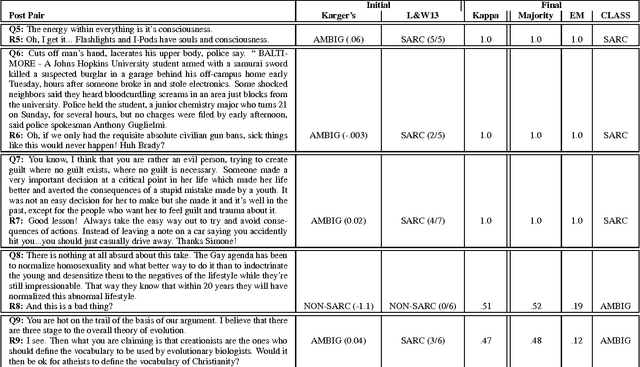
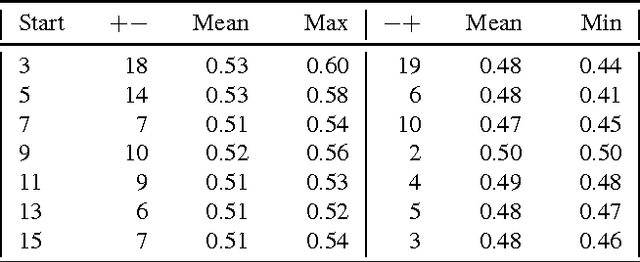
The language used in online forums differs in many ways from that of traditional language resources such as news. One difference is the use and frequency of nonliteral, subjective dialogue acts such as sarcasm. Whether the aim is to develop a theory of sarcasm in dialogue, or engineer automatic methods for reliably detecting sarcasm, a major challenge is simply the difficulty of getting enough reliably labelled examples. In this paper we describe our work on methods for achieving highly reliable sarcasm annotations from untrained annotators on Mechanical Turk. We explore the use of a number of common statistical reliability measures, such as Kappa, Karger's, Majority Class, and EM. We show that more sophisticated measures do not appear to yield better results for our data than simple measures such as assuming that the correct label is the one that a majority of Turkers apply.