 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN-Based Prediction of Frame-Level Shot Importance for Video Summarization
Paper and Code
Aug 23, 2017
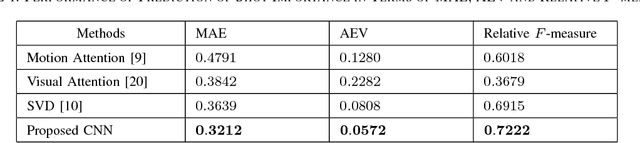
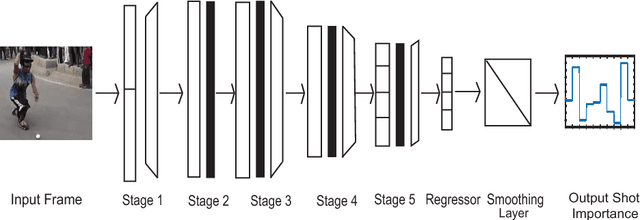
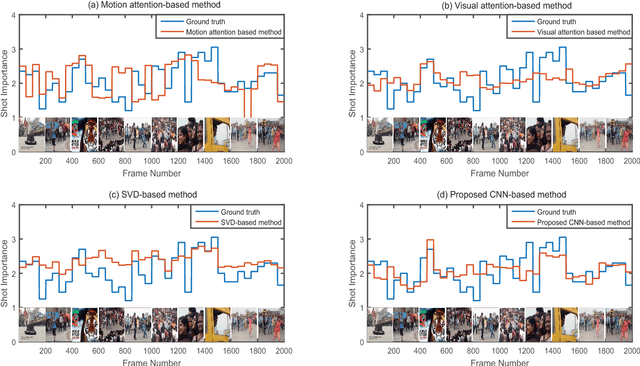
In the Internet, ubiquitous presence of redundant, unedited, raw videos has made video summarization an important problem. Traditional methods of video summarization employ a heuristic set of hand-crafted features, which in many cases fail to capture subtle abstraction of a scene. This paper presents a deep learning method that maps the context of a video to the importance of a scene similar to that is perceived by humans. In particular, a convolutional neural network (CNN)-based architecture is proposed to mimic the frame-level shot importance for user-oriented video summarization. The weights and biases of the CNN are trained extensively through off-line processing, so that it can provide the importance of a frame of an unseen video almost instantaneously. Experiments on estimating the shot importance is carried out using the publicly available database TVSum50. It is shown that the performance of the proposed network is substantially better than that of commonly referred feature-based methods for estimating the shot importance in terms of mean absolute error, absolute error variance, and relative F-measure.