 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Sets: Word Embeddings Learned from Tweets and General Data
Paper and Code
Aug 14, 2017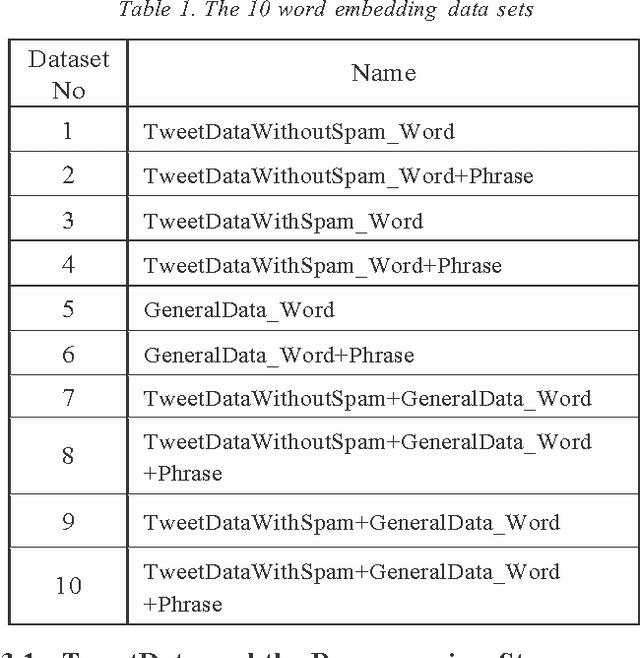
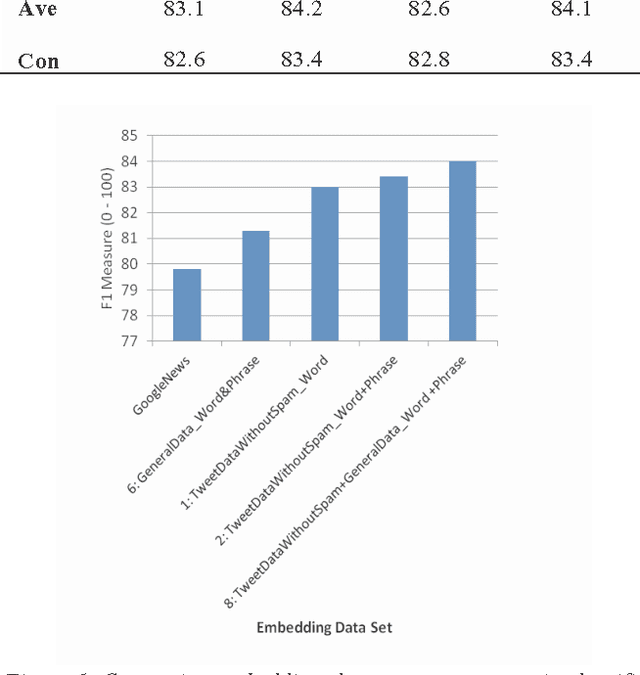
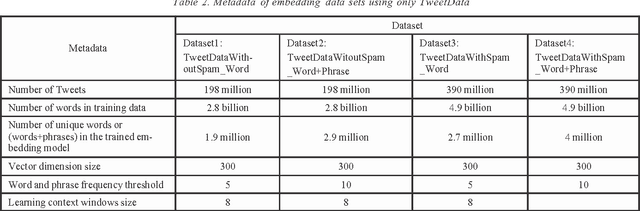
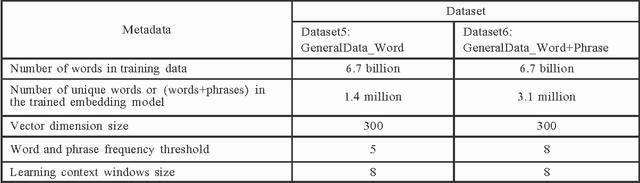
A word embedding is a low-dimensional, dense and real- valued vector representation of a word. Word embeddings have been used in many NLP tasks. They are usually gener- ated from a large text corpus. The embedding of a word cap- tures both its syntactic and semantic aspects. Tweets are short, noisy and have unique lexical and semantic features that are different from other types of text. Therefore, it is necessary to have word embeddings learned specifically from tweets. In this paper, we present ten word embedding data sets. In addition to the data sets learned from just tweet data, we also built embedding sets from the general data and the combination of tweets with the general data. The general data consist of news articles, Wikipedia data and other web data. These ten embedding models were learned from about 400 million tweets and 7 billion words from the general text. In this paper, we also present two experiments demonstrating how to use the data sets in some NLP tasks, such as tweet sentiment analysis and tweet topic classification tasks.