 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Theory of Distributed Regression with Bias Corrected Regularization Kernel Network
Paper and Code
Aug 07, 2017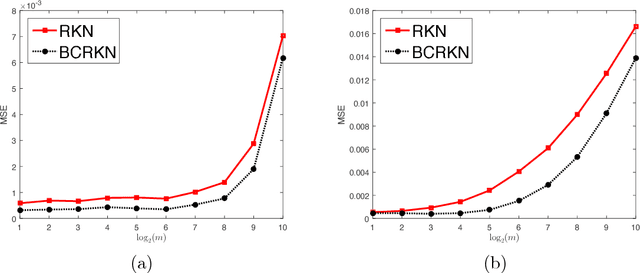
Distributed learning is an effective way to analyze big data. In distributed regression, a typical approach is to divide the big data into multiple blocks, apply a base regression algorithm on each of them, and then simply average the output functions learnt from these blocks. Since the average process will decrease the variance, not the bias, bias correction is expected to improve the learning performance if the base regression algorithm is a biased one. Regularization kernel network is an effective and widely used method for nonlinear regression analysis. In this paper we will investigate a bias corrected version of regularization kernel network. We derive the error bounds when it is applied to a single data set and when it is applied as a base algorithm in distributed regression. We show that, under certain appropriate conditions, the optimal learning rates can be reached in both situations.