 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShare your Model instead of your Data: Privacy Preserving Mimic Learning for Ranking
Paper and Code
Jul 24, 2017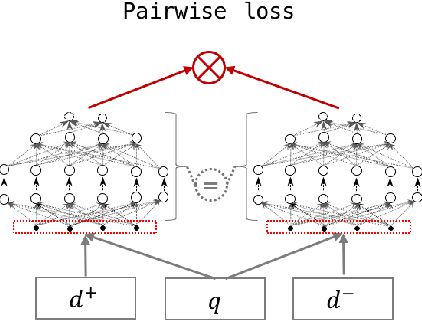

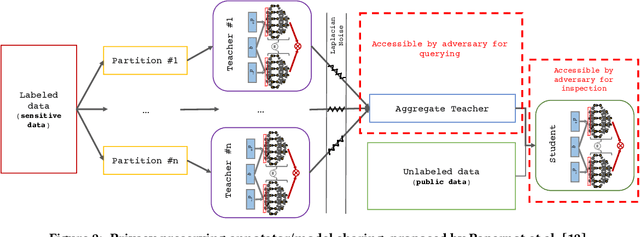
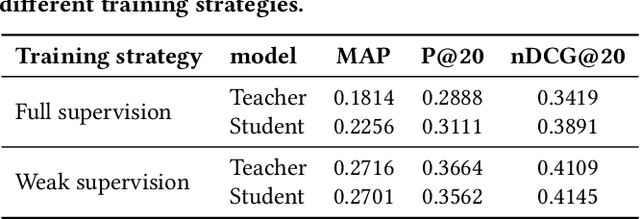
Deep neural networks have become a primary tool for solving problems in many fields. They are also used for addressing information retrieval problems and show strong performance in several tasks. Training these models requires large, representative datasets and for most IR tasks, such data contains sensitive information from users. Privacy and confidentiality concerns prevent many data owners from sharing the data, thus today the research community can only benefit from research on large-scale datasets in a limited manner. In this paper, we discuss privacy preserving mimic learning, i.e., using predictions from a privacy preserving trained model instead of labels from the original sensitive training data as a supervision signal. We present the results of preliminary experiments in which we apply the idea of mimic learning and privacy preserving mimic learning for the task of document re-ranking as one of the core IR tasks. This research is a step toward laying the ground for enabling researchers from data-rich environments to share knowledge learned from actual users' data, which should facilitate research collaborations.