 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Label Ambiguity for Neural List-Wise Learning to Rank
Paper and Code

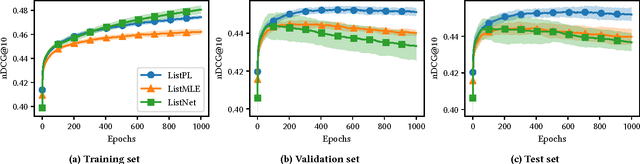
List-wise learning to rank methods are considered to be the state-of-the-art. One of the major problems with these methods is that the ambiguous nature of relevance labels in learning to rank data is ignored. Ambiguity of relevance labels refers to the phenomenon that multiple documents may be assigned the same relevance label for a given query, so that no preference order should be learned for those documents. In this paper we propose a novel sampling technique for computing a list-wise loss that can take into account this ambiguity. We show the effectiveness of the proposed method by training a 3-layer deep neural network. We compare our new loss function to two strong baselines: ListNet and ListMLE. We show that our method generalizes better and significantly outperforms other methods on the validation and test sets.