 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Iterative Deep Learning of Speech Features and Acoustic Tokens with Applications to Spoken Term Detection
Paper and Code
Jul 17, 2017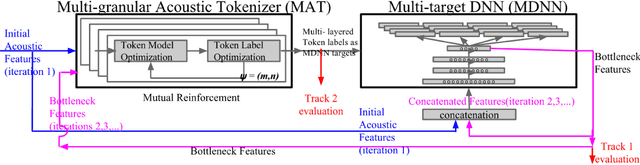
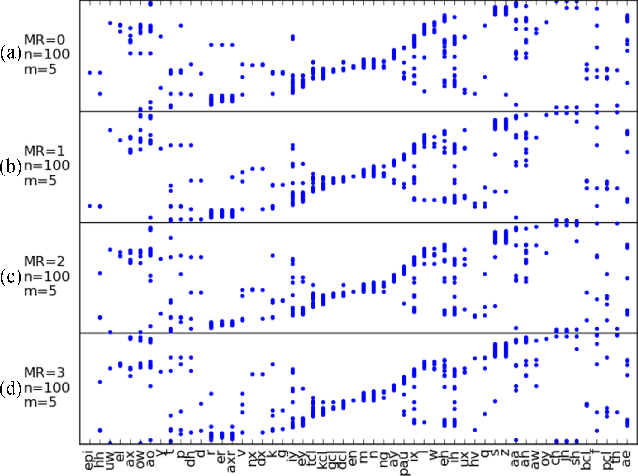
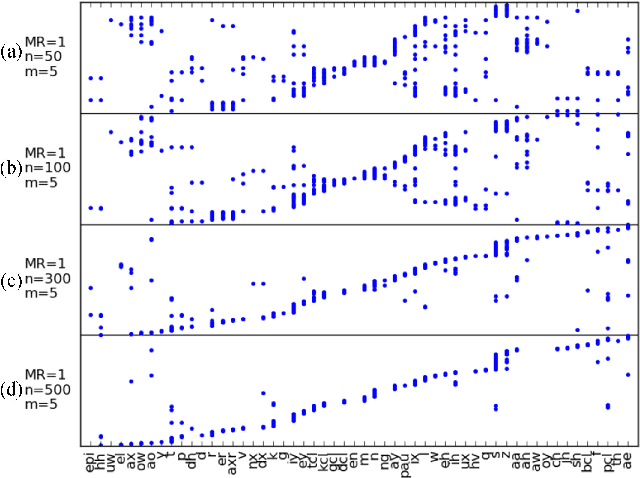
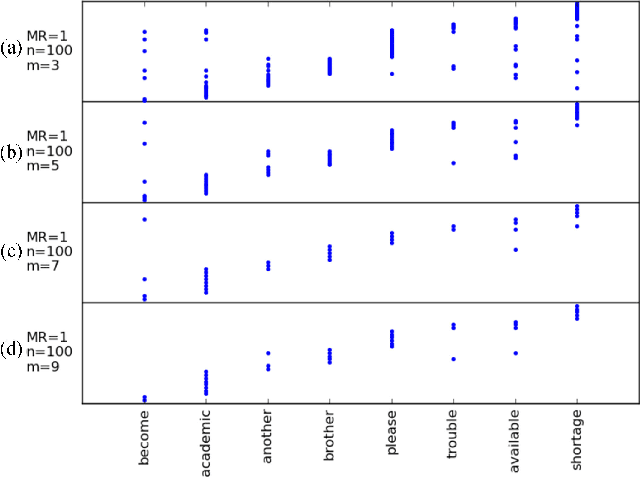
In this paper we aim to automatically discover high quality frame-level speech features and acoustic tokens directly from unlabeled speech data. A Multi-granular Acoustic Tokenizer (MAT) was proposed for automatic discovery of multiple sets of acoustic tokens from the given corpus. Each acoustic token set is specified by a set of hyperparameters describing the model configuration. These different sets of acoustic tokens carry different characteristics for the given corpus and the language behind, thus can be mutually reinforced. The multiple sets of token labels are then used as the targets of a Multi-target Deep Neural Network (MDNN) trained on frame-level acoustic features. Bottleneck features extracted from the MDNN are then used as the feedback input to the MAT and the MDNN itself in the next iteration. The multi-granular acoustic token sets and the frame-level speech features can be iteratively optimized in the iterative deep learning framework. We call this framework the Multi-granular Acoustic Tokenizing Deep Neural Network (MATDNN). The results were evaluated using the metrics and corpora defined in the Zero Resource Speech Challenge organized at Interspeech 2015, and improved performance was obtained with a set of experiments of query-by-example spoken term detection on the same corpora. Visualization for the discovered tokens against the English phonemes was also shown.