 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimedia Semantic Integrity Assessment Using Joint Embedding Of Images And Text
Paper and Code


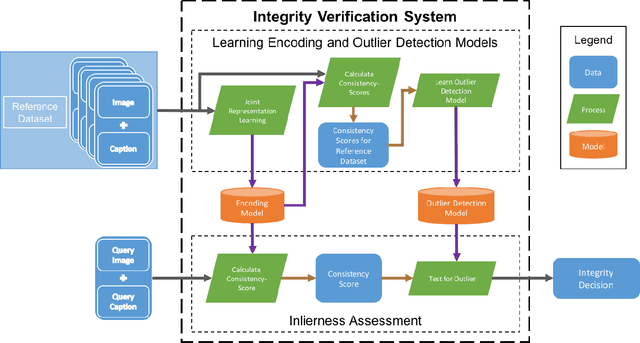

Real world multimedia data is often composed of multiple modalities such as an image or a video with associated text (e.g. captions, user comments, etc.) and metadata. Such multimodal data packages are prone to manipulations, where a subset of these modalities can be altered to misrepresent or repurpose data packages, with possible malicious intent. It is, therefore, important to develop methods to assess or verify the integrity of these multimedia packages. Using computer vision and natural language processing methods to directly compare the image (or video) and the associated caption to verify the integrity of a media package is only possible for a limited set of objects and scenes. In this paper, we present a novel deep learning-based approach for assessing the semantic integrity of multimedia packages containing images and captions, using a reference set of multimedia packages. We construct a joint embedding of images and captions with deep multimodal representation learning on the reference dataset in a framework that also provides image-caption consistency scores (ICCSs). The integrity of query media packages is assessed as the inlierness of the query ICCSs with respect to the reference dataset. We present the MultimodAl Information Manipulation dataset (MAIM), a new dataset of media packages from Flickr, which we make available to the research community. We use both the newly created dataset as well as Flickr30K and MS COCO datasets to quantitatively evaluate our proposed approach. The reference dataset does not contain unmanipulated versions of tampered query packages. Our method is able to achieve F1 scores of 0.75, 0.89 and 0.94 on MAIM, Flickr30K and MS COCO, respectively, for detecting semantically incoherent media packages.