 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Musical Context with Word2vec
Paper and Code
Jun 29, 2017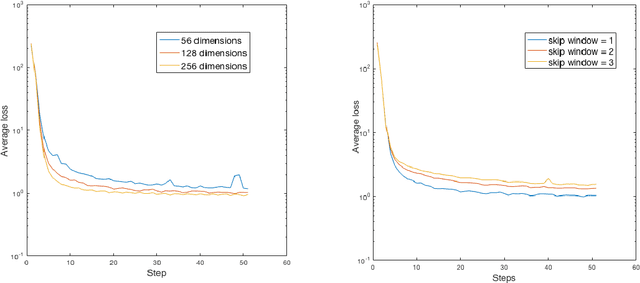
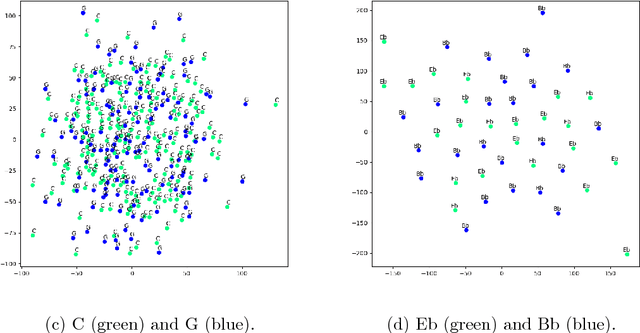

We present a semantic vector space model for capturing complex polyphonic musical context. A word2vec model based on a skip-gram representation with negative sampling was used to model slices of music from a dataset of Beethoven's piano sonatas. A visualization of the reduced vector space using t-distributed stochastic neighbor embedding shows that the resulting embedded vector space captures tonal relationships, even without any explicit information about the musical contents of the slices. Secondly, an excerpt of the Moonlight Sonata from Beethoven was altered by replacing slices based on context similarity. The resulting music shows that the selected slice based on similar word2vec context also has a relatively short tonal distance from the original slice.