 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn learning the structure of Bayesian Networks and submodular function maximization
Paper and Code
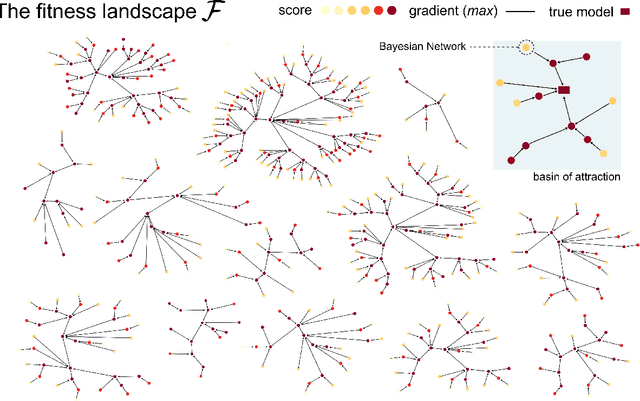
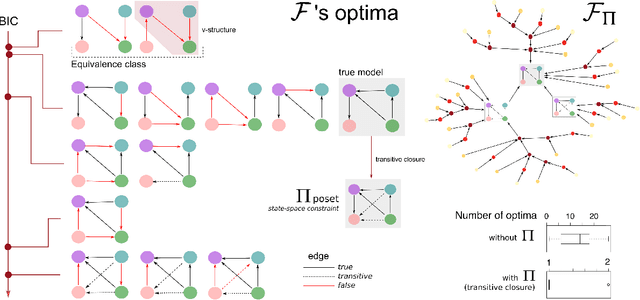
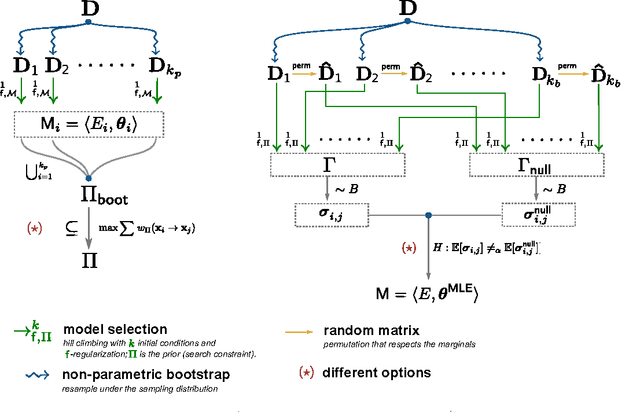
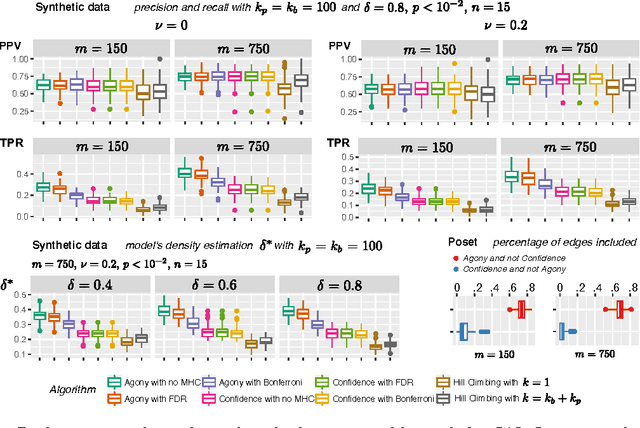
Learning the structure of dependencies among multiple random variables is a problem of considerable theoretical and practical interest. In practice, score optimisation with multiple restarts provides a practical and surprisingly successful solution, yet the conditions under which this may be a well founded strategy are poorly understood. In this paper, we prove that the problem of identifying the structure of a Bayesian Network via regularised score optimisation can be recast, in expectation, as a submodular optimisation problem, thus guaranteeing optimality with high probability. This result both explains the practical success of optimisation heuristics, and suggests a way to improve on such algorithms by artificially simulating multiple data sets via a bootstrap procedure. We show on several synthetic data sets that the resulting algorithm yields better recovery performance than the state of the art, and illustrate in a real cancer genomic study how such an approach can lead to valuable practical insights.