 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel clustering: density biases and solutions
Paper and Code
Dec 06, 2017

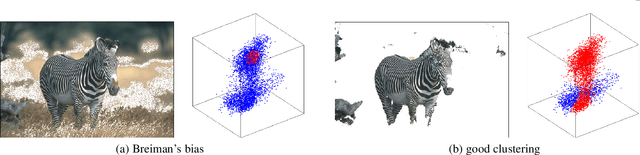
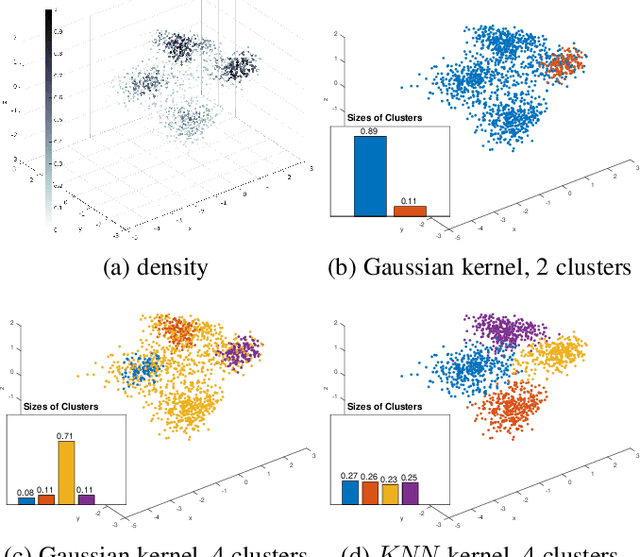
Kernel methods are popular in clustering due to their generality and discriminating power. However, we show that many kernel clustering criteria have density biases theoretically explaining some practically significant artifacts empirically observed in the past. For example, we provide conditions and formally prove the density mode isolation bias in kernel K-means for a common class of kernels. We call it Breiman's bias due to its similarity to the histogram mode isolation previously discovered by Breiman in decision tree learning with Gini impurity. We also extend our analysis to other popular kernel clustering methods, e.g. average/normalized cut or dominant sets, where density biases can take different forms. For example, splitting isolated points by cut-based criteria is essentially the sparsest subset bias, which is the opposite of the density mode bias. Our findings suggest that a principled solution for density biases in kernel clustering should directly address data inhomogeneity. We show that density equalization can be implicitly achieved using either locally adaptive weights or locally adaptive kernels. Moreover, density equalization makes many popular kernel clustering objectives equivalent. Our synthetic and real data experiments illustrate density biases and proposed solutions. We anticipate that theoretical understanding of kernel clustering limitations and their principled solutions will be important for a broad spectrum of data analysis applications across the disciplines.