 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Key-Foreign Key Joins Safe to Avoid when Learning High-Capacity Classifiers?
Paper and Code
Jun 04, 2017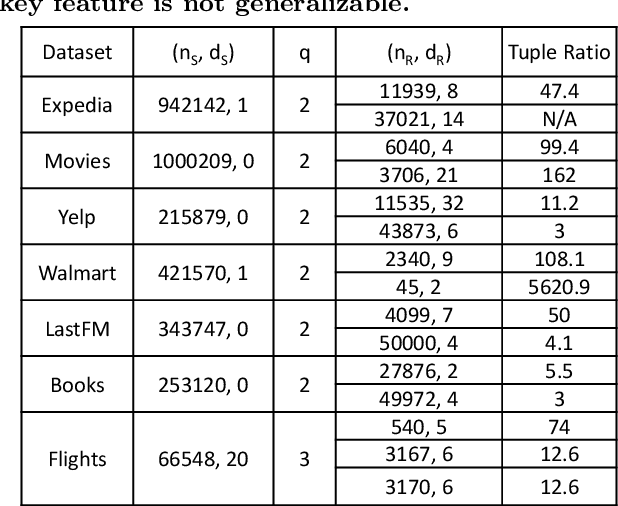
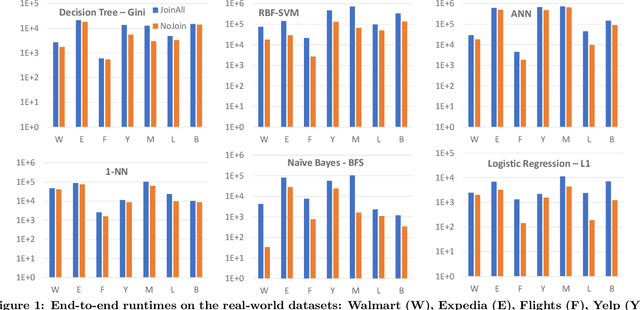
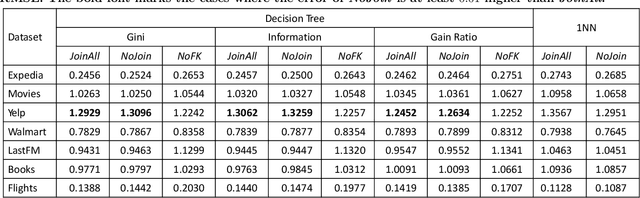
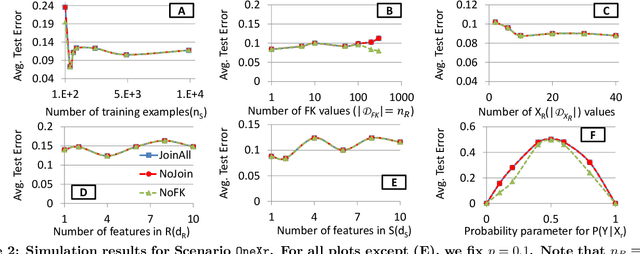
Machine learning (ML) over relational data is a booming area of the database industry and academia. While several projects aim to build scalable and fast ML systems, little work has addressed the pains of sourcing data and features for ML tasks. Real-world relational databases typically have many tables (often, dozens) and data scientists often struggle to even obtain and join all possible tables that provide features for ML. In this context, Kumar et al. showed recently that key-foreign key dependencies (KFKDs) between tables often lets us avoid such joins without significantly affecting prediction accuracy--an idea they called avoiding joins safely. While initially controversial, this idea has since been used by multiple companies to reduce the burden of data sourcing for ML. But their work applied only to linear classifiers. In this work, we verify if their results hold for three popular complex classifiers: decision trees, SVMs, and ANNs. We conduct an extensive experimental study using both real-world datasets and simulations to analyze the effects of avoiding KFK joins on such models. Our results show that these high-capacity classifiers are surprisingly and counter-intuitively more robust to avoiding KFK joins compared to linear classifiers, refuting an intuition from the prior work's analysis. We explain this behavior intuitively and identify open questions at the intersection of data management and ML theoretical research. All of our code and datasets are available for download from http://cseweb.ucsd.edu/~arunkk/hamlet.