 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Holistic Approach for Optimizing DSP Block Utilization of a CNN implementation on FPGA
Paper and Code
Mar 21, 2017
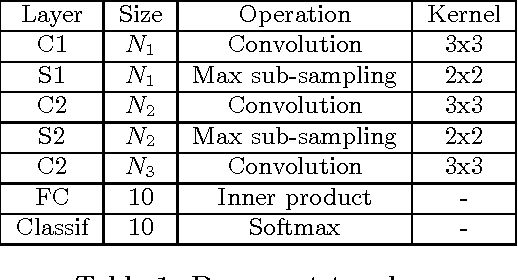
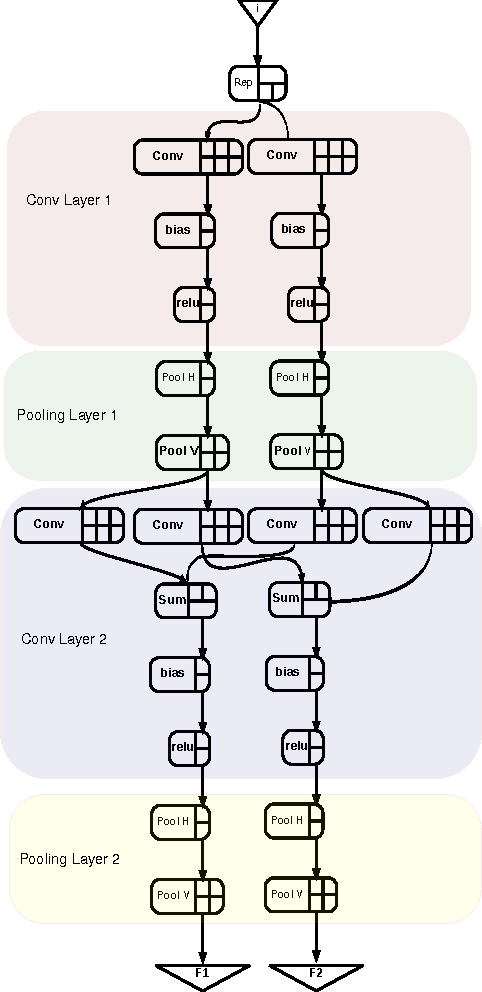

Deep Neural Networks are becoming the de-facto standard models for image understanding, and more generally for computer vision tasks. As they involve highly parallelizable computations, CNN are well suited to current fine grain programmable logic devices. Thus, multiple CNN accelerators have been successfully implemented on FPGAs. Unfortunately, FPGA resources such as logic elements or DSP units remain limited. This work presents a holistic method relying on approximate computing and design space exploration to optimize the DSP block utilization of a CNN implementation on an FPGA. This method was tested when implementing a reconfigurable OCR convolutional neural network on an Altera Stratix V device and varying both data representation and CNN topology in order to find the best combination in terms of DSP block utilization and classification accuracy. This exploration generated dataflow architectures of 76 CNN topologies with 5 different fixed point representation. Most efficient implementation performs 883 classifications/sec at 256 x 256 resolution using 8% of the available DSP blocks.