 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extended Framework for Marginalized Domain Adaptation
Paper and Code
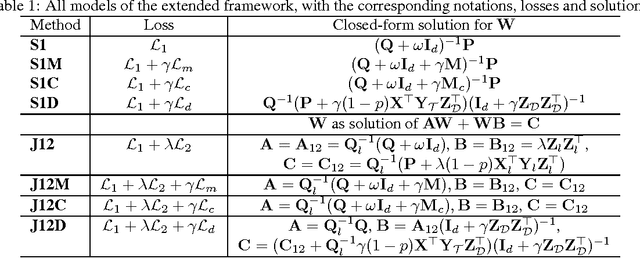
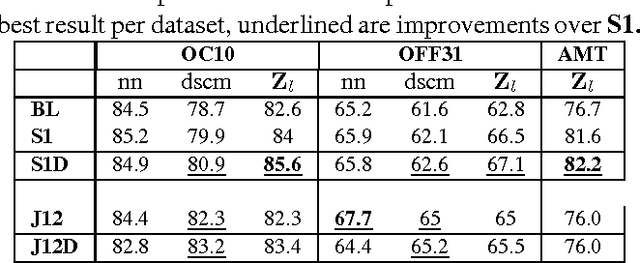
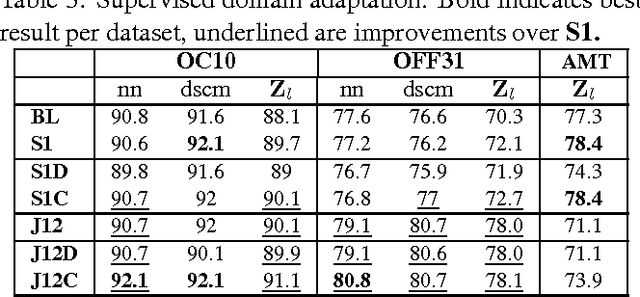
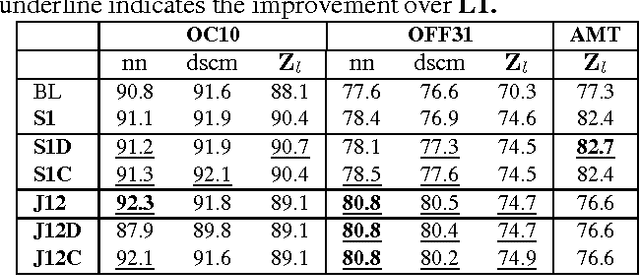
We propose an extended framework for marginalized domain adaptation, aimed at addressing unsupervised, supervised and semi-supervised scenarios. We argue that the denoising principle should be extended to explicitly promote domain-invariant features as well as help the classification task. Therefore we propose to jointly learn the data auto-encoders and the target classifiers. First, in order to make the denoised features domain-invariant, we propose a domain regularization that may be either a domain prediction loss or a maximum mean discrepancy between the source and target data. The noise marginalization in this case is reduced to solving the linear matrix system $AX=B$ which has a closed-form solution. Second, in order to help the classification, we include a class regularization term. Adding this component reduces the learning problem to solving a Sylvester linear matrix equation $AX+BX=C$, for which an efficient iterative procedure exists as well. We did an extensive study to assess how these regularization terms improve the baseline performance in the three domain adaptation scenarios and present experimental results on two image and one text benchmark datasets, conventionally used for validating domain adaptation methods. We report our findings and comparison with state-of-the-art methods.