 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Embedding of Wikipedia Concepts and Entities
Paper and Code

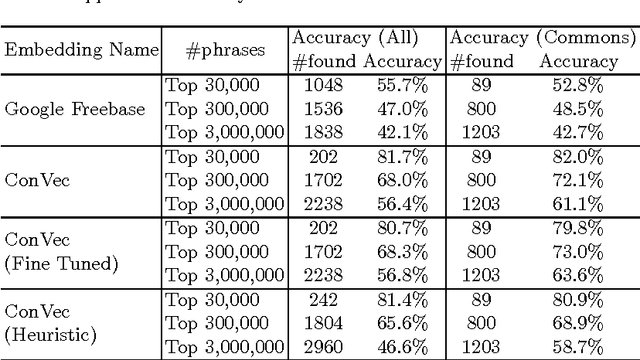
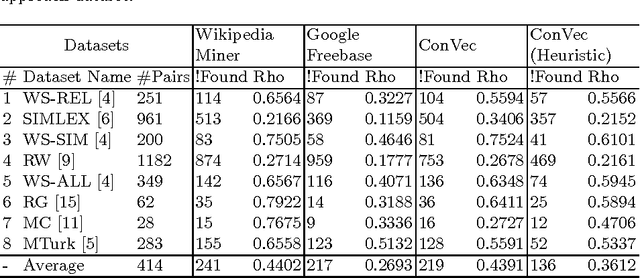
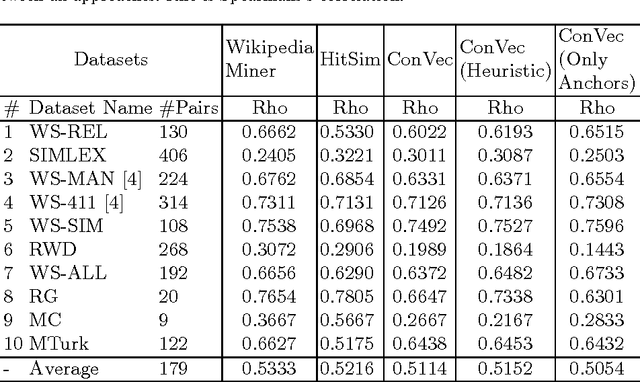
Using deep learning for different machine learning tasks such as image classification and word embedding has recently gained many attentions. Its appealing performance reported across specific Natural Language Processing (NLP) tasks in comparison with other approaches is the reason for its popularity. Word embedding is the task of mapping words or phrases to a low dimensional numerical vector. In this paper, we use deep learning to embed Wikipedia Concepts and Entities. The English version of Wikipedia contains more than five million pages, which suggest its capability to cover many English Entities, Phrases, and Concepts. Each Wikipedia page is considered as a concept. Some concepts correspond to entities, such as a person's name, an organization or a place. Contrary to word embedding, Wikipedia Concepts Embedding is not ambiguous, so there are different vectors for concepts with similar surface form but different mentions. We proposed several approaches and evaluated their performance based on Concept Analogy and Concept Similarity tasks. The results show that proposed approaches have the performance comparable and in some cases even higher than the state-of-the-art methods.