 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model-based Projection Technique for Segmenting Customers
Paper and Code
Jan 25, 2017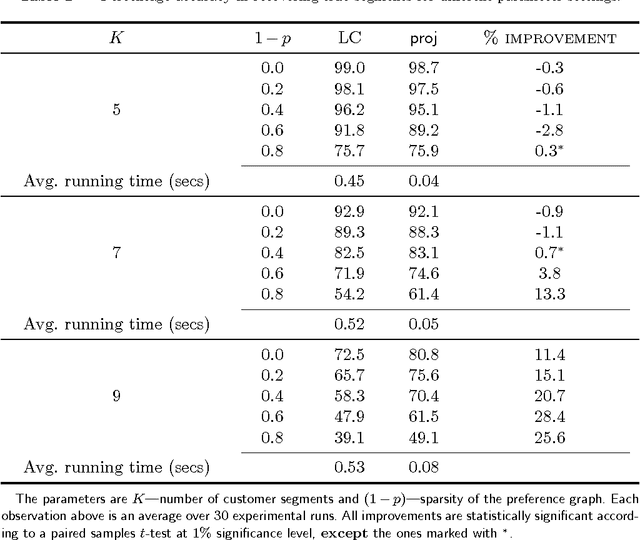
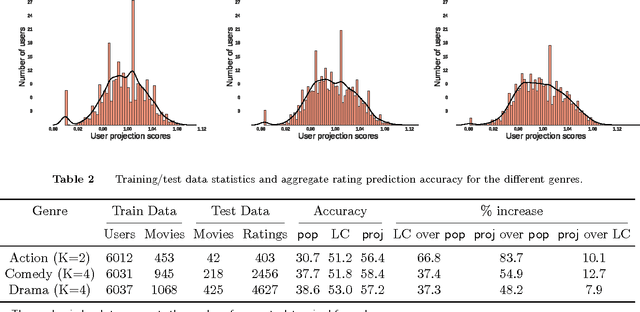
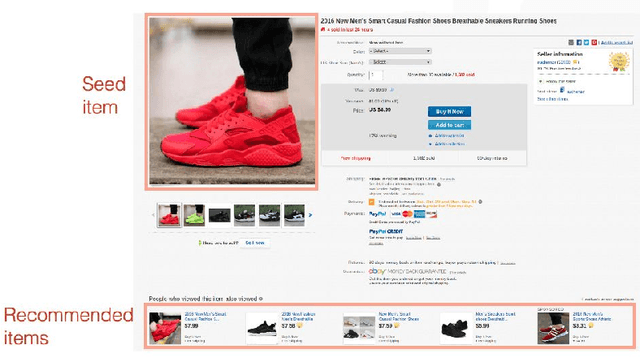
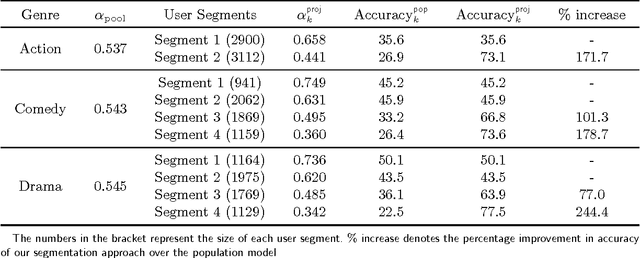
We consider the problem of segmenting a large population of customers into non-overlapping groups with similar preferences, using diverse preference observations such as purchases, ratings, clicks, etc. over subsets of items. We focus on the setting where the universe of items is large (ranging from thousands to millions) and unstructured (lacking well-defined attributes) and each customer provides observations for only a few items. These data characteristics limit the applicability of existing techniques in marketing and machine learning. To overcome these limitations, we propose a model-based projection technique, which transforms the diverse set of observations into a more comparable scale and deals with missing data by projecting the transformed data onto a low-dimensional space. We then cluster the projected data to obtain the customer segments. Theoretically, we derive precise necessary and sufficient conditions that guarantee asymptotic recovery of the true customer segments. Empirically, we demonstrate the speed and performance of our method in two real-world case studies: (a) 84% improvement in the accuracy of new movie recommendations on the MovieLens data set and (b) 6% improvement in the performance of similar item recommendations algorithm on an offline dataset at eBay. We show that our method outperforms standard latent-class and demographic-based techniques.