 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence-level dialects identification in the greater China region
Paper and Code
Jan 08, 2017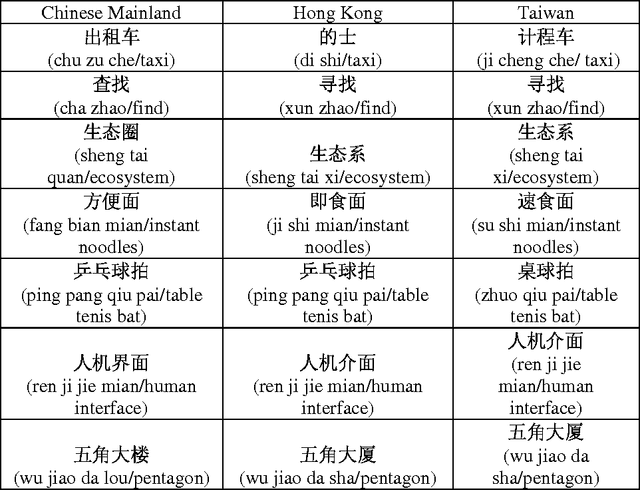



Identifying the different varieties of the same language is more challenging than unrelated languages identification. In this paper, we propose an approach to discriminate language varieties or dialects of Mandarin Chinese for the Mainland China, Hong Kong, Taiwan, Macao, Malaysia and Singapore, a.k.a., the Greater China Region (GCR). When applied to the dialects identification of the GCR, we find that the commonly used character-level or word-level uni-gram feature is not very efficient since there exist several specific problems such as the ambiguity and context-dependent characteristic of words in the dialects of the GCR. To overcome these challenges, we use not only the general features like character-level n-gram, but also many new word-level features, including PMI-based and word alignment-based features. A series of evaluation results on both the news and open-domain dataset from Wikipedia show the effectiveness of the proposed approach.