 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKS_JU@DPIL-FIRE2016:Detecting Paraphrases in Indian Languages Using Multinomial Logistic Regression Model
Paper and Code
Dec 24, 2016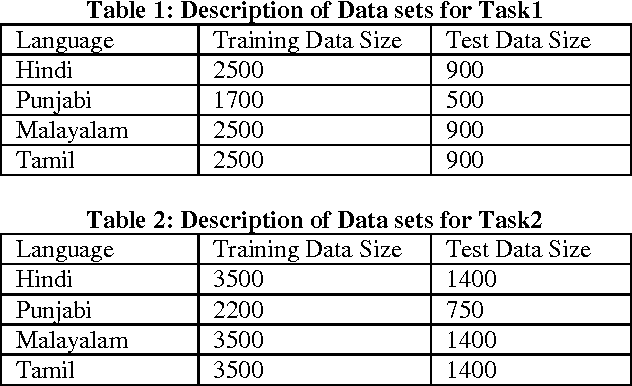
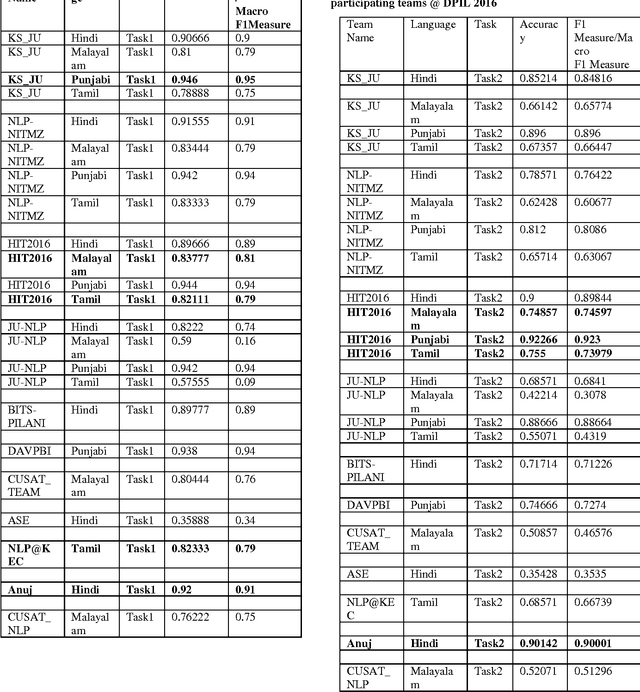
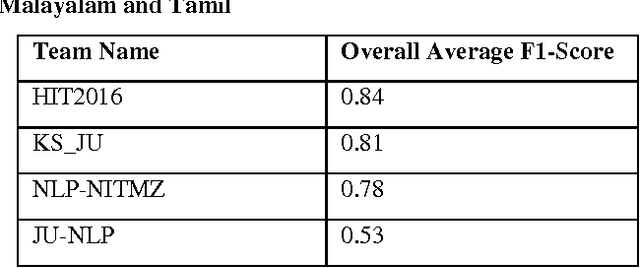
In this work, we describe a system that detects paraphrases in Indian Languages as part of our participation in the shared Task on detecting paraphrases in Indian Languages (DPIL) organized by Forum for Information Retrieval Evaluation (FIRE) in 2016. Our paraphrase detection method uses a multinomial logistic regression model trained with a variety of features which are basically lexical and semantic level similarities between two sentences in a pair. The performance of the system has been evaluated against the test set released for the FIRE 2016 shared task on DPIL. Our system achieves the highest f-measure of 0.95 on task1 in Punjabi language.The performance of our system on task1 in Hindi language is f-measure of 0.90. Out of 11 teams participated in the shared task, only four teams participated in all four languages, Hindi, Punjabi, Malayalam and Tamil, but the remaining 7 teams participated in one of the four languages. We also participated in task1 and task2 both for all four Indian Languages. The overall average performance of our system including task1 and task2 overall four languages is F1-score of 0.81 which is the second highest score among the four systems that participated in all four languages.