 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Anatomy Classification Through Attentive Response Maps
Paper and Code
Feb 07, 2018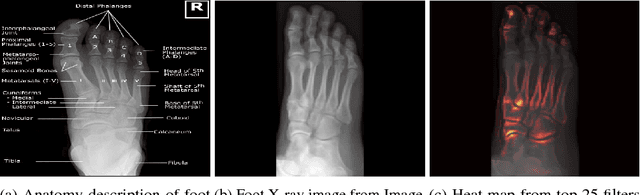
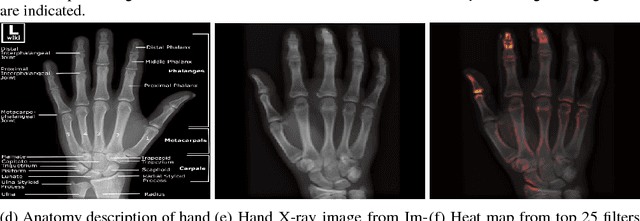

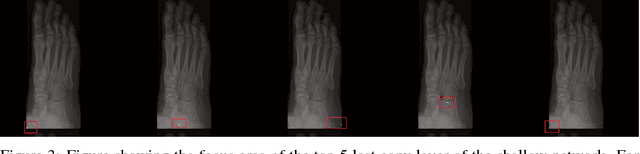
One of the main challenges for broad adoption of deep learning based models such as convolutional neural networks (CNN), is the lack of understanding of their decisions. In many applications, a simpler, less capable model that can be easily understood is favorable to a black-box model that has superior performance. In this paper, we present an approach for designing CNNs based on visualization of the internal activations of the model. We visualize the model's response through attentive response maps obtained using a fractional stride convolution technique and compare the results with known imaging landmarks from the medical literature. We show that sufficiently deep and capable models can be successfully trained to use the same medical landmarks a human expert would use. Our approach allows for communicating the model decision process well, but also offers insight towards detecting biases.