 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrusting SVM for Piecewise Linear CNNs
Paper and Code

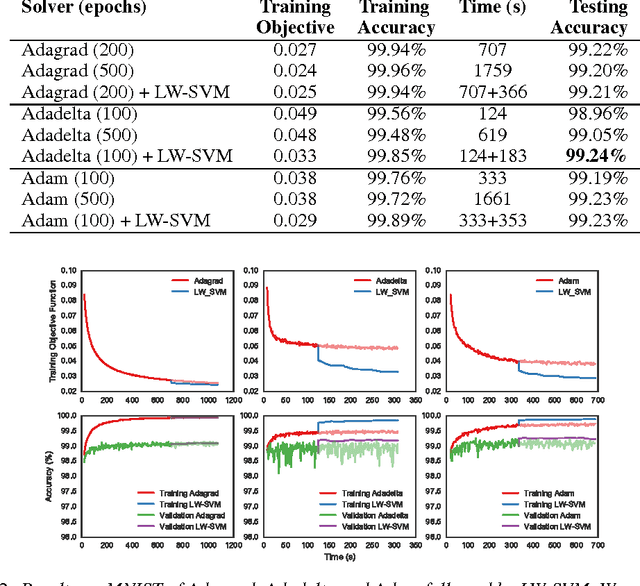
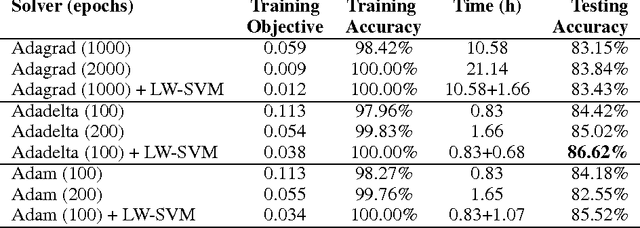

We present a novel layerwise optimization algorithm for the learning objective of Piecewise-Linear Convolutional Neural Networks (PL-CNNs), a large class of convolutional neural networks. Specifically, PL-CNNs employ piecewise linear non-linearities such as the commonly used ReLU and max-pool, and an SVM classifier as the final layer. The key observation of our approach is that the problem corresponding to the parameter estimation of a layer can be formulated as a difference-of-convex (DC) program, which happens to be a latent structured SVM. We optimize the DC program using the concave-convex procedure, which requires us to iteratively solve a structured SVM problem. This allows to design an optimization algorithm with an optimal learning rate that does not require any tuning. Using the MNIST, CIFAR and ImageNet data sets, we show that our approach always improves over the state of the art variants of backpropagation and scales to large data and large network settings.