 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Assortment Personalization in High Dimensions
Paper and Code
Sep 29, 2017
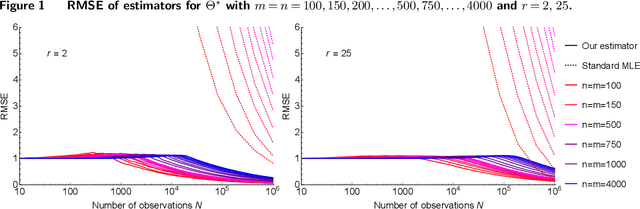
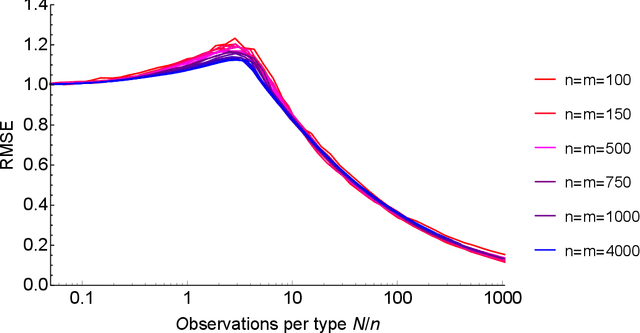
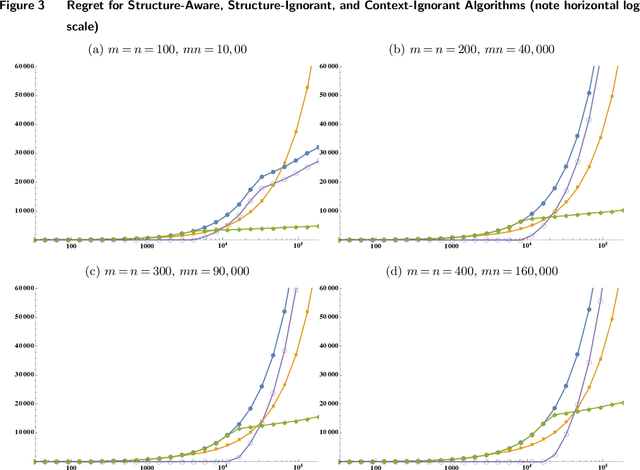
We study the problem of dynamic assortment personalization with large, heterogeneous populations and wide arrays of products, and demonstrate the importance of structural priors for effective, efficient large-scale personalization. Assortment personalization is the problem of choosing, for each individual or consumer segment (type), a best assortment of products, ads, or other offerings (items) so as to maximize revenue. This problem is central to revenue management in e-commerce, online advertising, and multi-location brick-and-mortar retail, where both items and types can number in the millions. We formulate the dynamic assortment personalization problem as a discrete-contextual bandit with $m$ contexts (customer types) and exponentially many arms (assortments of the $n$ items). We assume that each type's preferences follow a simple parametric model with $n$ parameters. In all, there are $mn$ parameters, and existing literature suggests that order optimal regret scales as $mn$. However, the data required to estimate so many parameters is orders of magnitude larger than the data available in most revenue management applications; and the optimal regret under these models is unacceptably high. In this paper, we impose a natural structure on the problem -- a small latent dimension, or low rank. In the static setting, we show that this model can be efficiently learned from surprisingly few interactions, using a time- and memory-efficient optimization algorithm that converges globally whenever the model is learnable. In the dynamic setting, we show that structure-aware dynamic assortment personalization can have regret that is an order of magnitude smaller than structure-ignorant approaches. We validate our theoretical results empirically.