 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbracing data abundance: BookTest Dataset for Reading Comprehension
Paper and Code

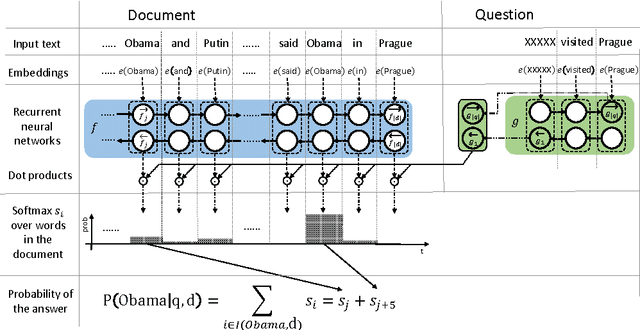
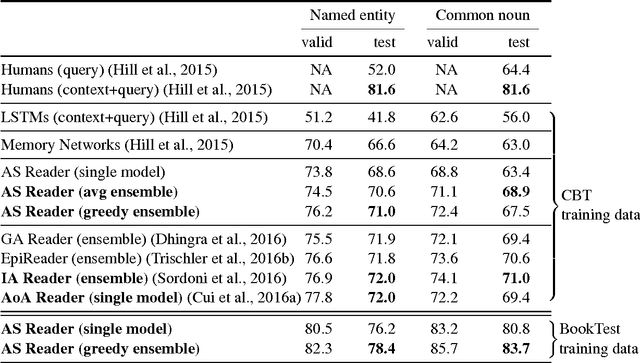

There is a practically unlimited amount of natural language data available. Still, recent work in text comprehension has focused on datasets which are small relative to current computing possibilities. This article is making a case for the community to move to larger data and as a step in that direction it is proposing the BookTest, a new dataset similar to the popular Children's Book Test (CBT), however more than 60 times larger. We show that training on the new data improves the accuracy of our Attention-Sum Reader model on the original CBT test data by a much larger margin than many recent attempts to improve the model architecture. On one version of the dataset our ensemble even exceeds the human baseline provided by Facebook. We then show in our own human study that there is still space for further improvement.