 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual RNN-GANs for Abstract Reasoning Diagram Generation
Paper and Code
Dec 06, 2016
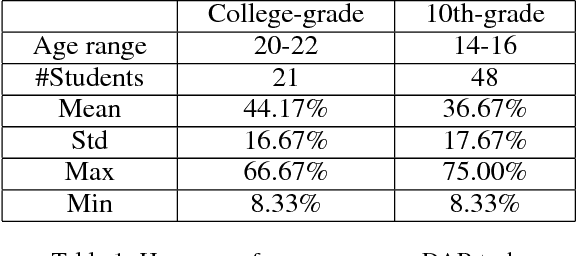
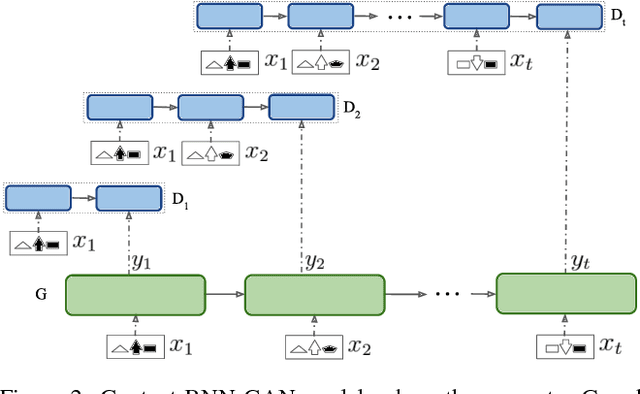
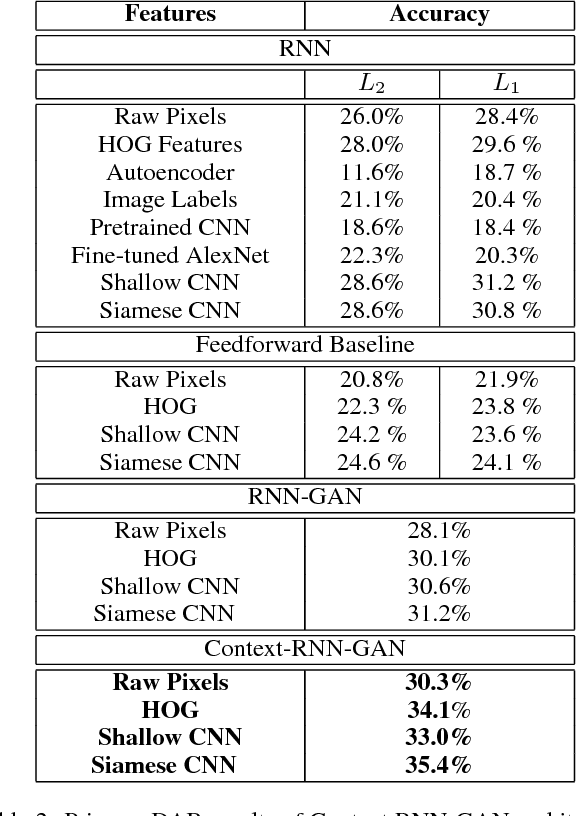
Understanding, predicting, and generating object motions and transformations is a core problem in artificial intelligence. Modeling sequences of evolving images may provide better representations and models of motion and may ultimately be used for forecasting, simulation, or video generation. Diagrammatic Abstract Reasoning is an avenue in which diagrams evolve in complex patterns and one needs to infer the underlying pattern sequence and generate the next image in the sequence. For this, we develop a novel Contextual Generative Adversarial Network based on Recurrent Neural Networks (Context-RNN-GANs), where both the generator and the discriminator modules are based on contextual history (modeled as RNNs) and the adversarial discriminator guides the generator to produce realistic images for the particular time step in the image sequence. We evaluate the Context-RNN-GAN model (and its variants) on a novel dataset of Diagrammatic Abstract Reasoning, where it performs competitively with 10th-grade human performance but there is still scope for interesting improvements as compared to college-grade human performance. We also evaluate our model on a standard video next-frame prediction task, achieving improved performance over comparable state-of-the-art.