 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-view Dimensionality Reduction for Dialect Identification of Arabic Broadcast Speech
Paper and Code
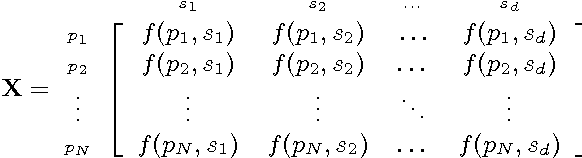
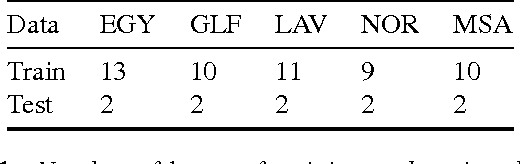
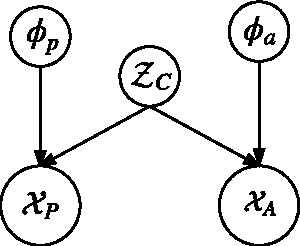

In this work, we present a new Vector Space Model (VSM) of speech utterances for the task of spoken dialect identification. Generally, DID systems are built using two sets of features that are extracted from speech utterances; acoustic and phonetic. The acoustic and phonetic features are used to form vector representations of speech utterances in an attempt to encode information about the spoken dialects. The Phonotactic and Acoustic VSMs, thus formed, are used for the task of DID. The aim of this paper is to construct a single VSM that encodes information about spoken dialects from both the Phonotactic and Acoustic VSMs. Given the two views of the data, we make use of a well known multi-view dimensionality reduction technique known as Canonical Correlation Analysis (CCA), to form a single vector representation for each speech utterance that encodes dialect specific discriminative information from both the phonetic and acoustic representations. We refer to this approach as feature space combination approach and show that our CCA based feature vector representation performs better on the Arabic DID task than the phonetic and acoustic feature representations used alone. We also present the feature space combination approach as a viable alternative to the model based combination approach, where two DID systems are built using the two VSMs (Phonotactic and Acoustic) and the final prediction score is the output score combination from the two systems.