 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Specific Hardness of Learning Neural Networks
Paper and Code
Mar 09, 2017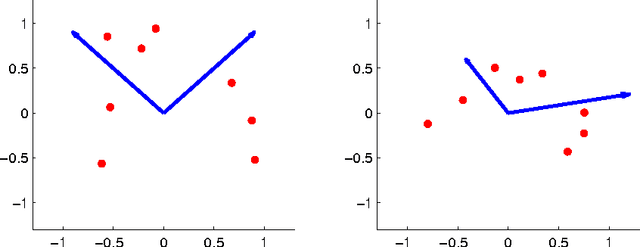
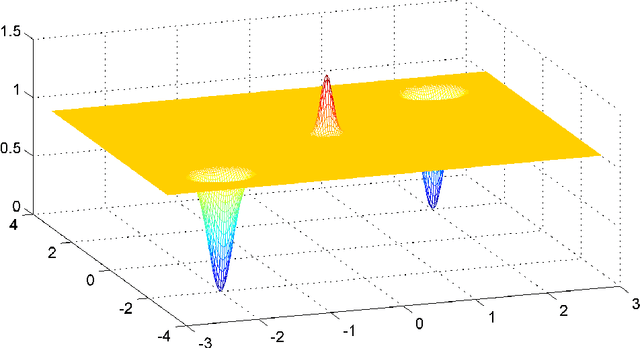
Although neural networks are routinely and successfully trained in practice using simple gradient-based methods, most existing theoretical results are negative, showing that learning such networks is difficult, in a worst-case sense over all data distributions. In this paper, we take a more nuanced view, and consider whether specific assumptions on the "niceness" of the input distribution, or "niceness" of the target function (e.g. in terms of smoothness, non-degeneracy, incoherence, random choice of parameters etc.), are sufficient to guarantee learnability using gradient-based methods. We provide evidence that neither class of assumptions alone is sufficient: On the one hand, for any member of a class of "nice" target functions, there are difficult input distributions. On the other hand, we identify a family of simple target functions, which are difficult to learn even if the input distribution is "nice". To prove our results, we develop some tools which may be of independent interest, such as extending Fourier-based hardness techniques developed in the context of statistical queries \cite{blum1994weakly}, from the Boolean cube to Euclidean space and to more general classes of functions.